
免责声明:如使用本脚本对目标服务器造成严重影响,本人概不负责!
以下内容包“AI 创作”,请注意辨别!
什么是Python爬虫?
Python爬虫是使用Python编程语言编写的网络爬虫程序。Python具有简洁易读的语法和丰富的第三方库支持,使其成为开发爬虫的热门选择。开发者可以利用Python的库(如Requests、Beautiful Soup、Scrapy等)来编写爬虫程序,实现自动化地访问网页、提取信息并进行数据处理的功能。Python爬虫在网络数据采集、信息监测、搜索引擎优化等领域有着广泛的应用。
本脚本仅用于检测速率请求限制或其他限制是否已生效或启用!
如何安装Python?
访问Python官方网站:Welcome to Python.org

下载Python的最新版本,安装
在安装的过程中,最好选择添加环境变量
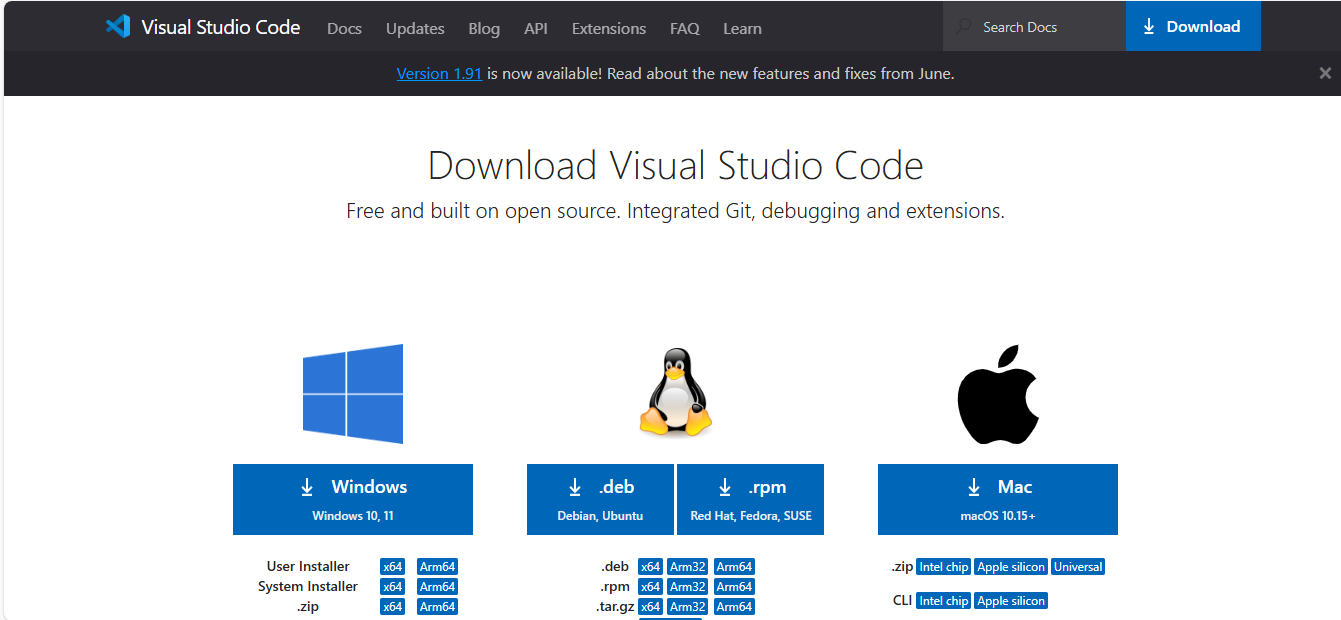
安装Visual Studio Code
您可以在官方网站 下载 Visual Studio Code – Mac, Linux, Windows 中选择适合您的版本进行下载。
创建第一个Python文件
您可以在电脑上的任意位置创建一个.txt文件,然后将文件的扩展名改为.py。
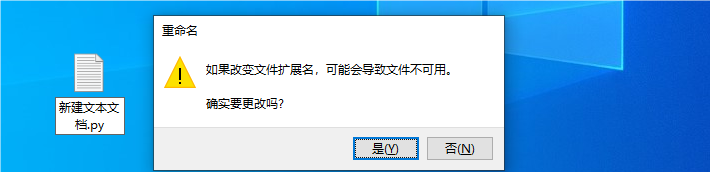
在弹出的选择框里选择是。
然后右键,在菜单中选择打开方式
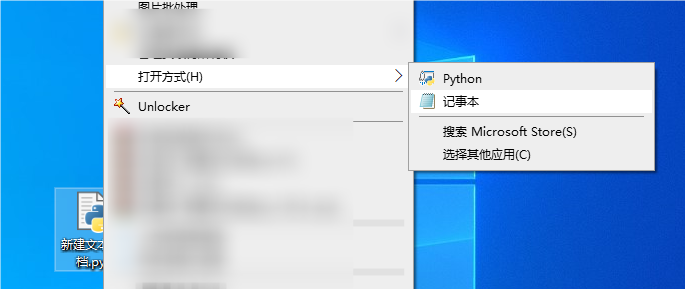
设置为“记事本”或者”Visual Studio Code”
Visual Studio Code需要安装Python插件,你可以在网上找到相关教程进行安装,这里不提供演示。
在弹出的文本编辑框里,输入以下内容:
import osimport requestsfrom concurrent.futures import ThreadPoolExecutor, as_completedimport turtleimport timeimport tkinter as tkfrom tkinter import simpledialog, messageboximport threadingdef download_image_chunked(url, image_dir, image_name): response = requests.get(url, stream=True) if response.status_code == 200: file_path = os.path.join(image_dir, image_name) with open(file_path, 'wb') as f: for chunk in response.iter_content(chunk_size=8192): # 8192 bytes per chunk if chunk: f.write(chunk) print(f"Image saved as {file_path}") else: print("Failed to download the image.")def submit_tasks_with_delay(executor, url, image_dir, count, interval): for i in range(count): image_name = f'image_{i}.png' # 使用一个单独的线程来等待,并在等待后提交任务 threading.Timer(interval * i, executor.submit, args=(download_image_chunked, url, image_dir, image_name)).start()def main(url, image_dir, count, interval): if not os.path.exists(image_dir): os.makedirs(image_dir) # 显示开始消息 messagebox.showinfo("开始", "开始拉取,将保存在Image文件夹中") # 初始化线程池 with ThreadPoolExecutor(max_workers=64) as executor: # 使用一个单独的线程来逐个提交任务,并添加间隔 submit_tasks_with_delay(executor, url, image_dir, count, interval) # 等待所有任务完成(由于我们使用了Timer,这里没有直接的方式等待所有任务) # 但我们可以等待足够长的时间,或者添加其他逻辑来检查任务是否完成 time.sleep(interval * count) # 这只是一个示例,可能并不准确 # 显示结束消息(注意:这可能会提前显示,因为不能保证所有任务都已完成)def delayed_download(url, image_dir, image_name, interval): # 添加一个带延迟的下载函数 time.sleep(interval) # 等待指定的时间间隔 download_image_chunked(url, image_dir, image_name)def get_input(): root = tk.Tk() root.withdraw() # 隐藏主窗口 url = simpledialog.askstring("输入", "请输入要爬取的链接:", parent=root) count = simpledialog.askinteger("输入", "请输入要爬取图片的数量:", parent=root) interval = simpledialog.askfloat("输入", "请输入图片下载间隔(秒):", parent=root) # 添加间隔输入 if url and count > 0 and interval >= 0: # 确保间隔是非负的 main(url, 'Image', count, interval) # 调用main函数时传入interval参数 else: messagebox.showerror("错误", "无效的输入,请重新输入。")if __name__ == "__main__": get_input()安装必要的库
在Cmd窗口中依次输入
pip install requests pip install turtle pip install tk
等待命令执行完成…….
运行脚本
在弹出的白色框中输入内容,即可开始爬取图片。
如果你不想安装Python,那么可以下载打包好的Python文件:点我下载main.exe
推荐本站淘宝优惠价购买喜欢的宝贝:

本文链接:https://www.hqyman.cn/post/7583.html 非本站原创文章欢迎转载,原创文章需保留本站地址!

 微信支付宝扫一扫,打赏作者吧~
微信支付宝扫一扫,打赏作者吧~休息一下~~