前提:下载安装VMware,安装centos系统
1- 登录虚拟机查看IP地址
ifconfig
若没有这个命令,安装
yum install -y net-tools.x86_64
执行ifconfig 找到 ip地址。使用xshell等工具连接上,主要是方便拷贝等操作。
2- 设置静态IP
网络必须是桥接 NAT模式(默认的网络设置),找到网卡并编辑,设置模式为 static,网关等。
2.1- 在虚拟机的右上角,'编辑' -> 虚拟机网络设置

2.2- 选择 NAT,并点击以 ‘’更改配置‘’

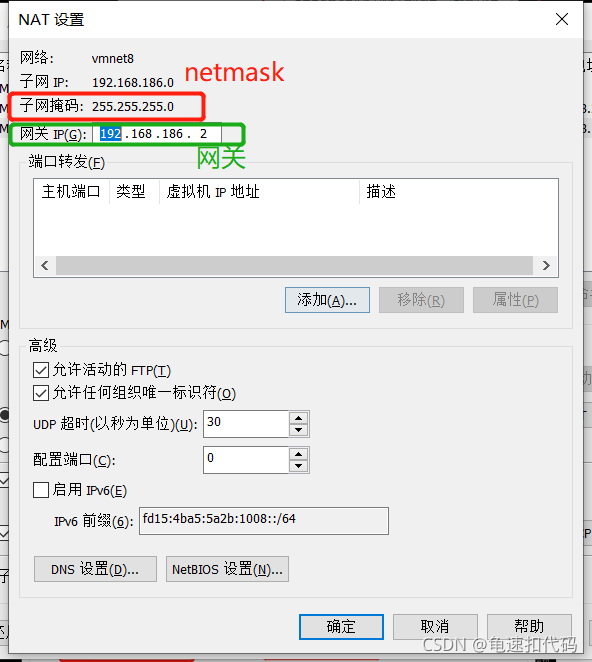
2.3- 选择NAT模式,点击NAT设置。
2.4- 设置并记下 NETMASK 和 网关地址。后面要用
这里是255.255.255.0 和 192.168.186.2
2.5- 在节点内,找到并编辑网络配置
ll /etc/sysconfig/network-scripts/

vi /etc/sysconfig/network-scripts/ifcfg-ens33
这里的 IPADDR为我们期望的静态IP地址, DNS1和GATEWAY是我们上面设置的网关地址。
NETMASK也是我们更改设置的。
ONBOOT=YES
OTPOTO="static"
DNS1=192.168.186.2
IPADDR=192.168.186.121
NETMASK=255.255.255.0
GATEWAY=192.168.186.2
3- 修改主机名
以node121为名
vi /etc/hostname
node121
4- 关闭防火墙
# 为了方便后续学习,这里是永久取消防火墙
systemctl disable firewalld
5- 重启节点
执行命令
reboot
查看设置静态IP是否起效果,执行ifconfig,

6- 克隆虚拟机,搭建集群
6.1- VMware上,鼠标右击 虚拟机,管理 -> 克隆
都点击下一步就好,磁盘这步选一下就可以
6.2- 修改克隆机子的IP为,我们设计的。
这里我设计的是192.168.186.122和 192.168.186.123
6.2.1- 启动 node122,因为此时ip和 node121一致,所以确保node121没有开启
6.2.2- 修改 主机名和 静态IP 为 预定的值 (/etc/hostname 和 /etc/sysconfig/network-scripts/ifcfg-ens33两个文件)
主机名:node122
IP:192.168.186.122
6.2.3- 关闭node122.
对node123重复 node122的操作。修改主机名和静态IP地址
主机名:node123
IP:192.168.186.123
7- 配置集群免密登录
7.1- 编辑 /etc/hosts
方便后续以节点名字访问。以在节点 node121 为例
vi /etc/hosts
192.168.186.121 node121
192.168.186.122 node122
192.168.186.123 node123
7.2- 生产秘钥
ssh-keygen -t rsa
一直按确认就好了

默认在 /root/.ssh目录下, 带pub的是公钥,母带的是私钥

7.3- 将公钥拷贝到3个节点 (自己也要)
为了方便后续的SCP,rsync等 在集群间的操作。
ssh-copy-id -i ~/.ssh/id_rsa.pub root@node121
ssh-copy-id -i ~/.ssh/id_rsa.pub root@node122
ssh-copy-id -i ~/.ssh/id_rsa.pub root@node123

检查免密登录设置是否成功

node122 和 node123重复 上述操作
8- 同步集群时间
只是搭建集群学习大数据用的。所以为了方便,直接三台定时同步外网时间。设置每10分钟取美国标准技术同步时间
在3台机子执行
crontab -e
*/10 * * * * ntpdate 202.120.2.101
学习大数据的集群搭建完成。后续的java和其他软件就自行安装。也可参考我的安装文档
大数据学习之组件安装_zhang5324496的博客-CSDN博客
到现在的部署情况来说,学习的机子集群已经搭建完成。但是为了方便后续的安装部署,和服务访问验证。还可以增加两步(不是必须,但是做了更方便后续的操作)
方便组件在集群的安装部署
组件的安装部署,需要在每个节点上进行。在学习的阶段一般没有CDH或者Ambari平台。需要自己在所有的节点上编写,太麻烦了。可以用一下三种方法进行集群 所有节点一起编写。(推荐最后一种脚本的使用)
1- 使用Xshell软件的 所有会话 编写功能
使用Xshell连接所有节点后,打开 “工具” --> “发送键输入到所有的会话”
此时你可以在软件的上方看到这个开关,当你不需要一起编写所有的会话窗口时,就可以点击"关闭 "

这种操作可以同时编写相同内容到所有的会话窗口。
2- 先安装好一个节点后,使用 SCP命令 将软件安装好的目录 拷贝到 其他节点(机器)
scp -r /安装目录 目标节点:/目标目录
例如
scp -r /opt/cluster/server/hadoop-2.9.2 node122:/opt/
3- 先安装好一个节点后,使用 rsync命令,将软件安装好的目录拷贝到其他节点上
rsync相对于 scp来说,它只拷贝 有差异的文件,所以速度会更快
# 参数就不详解了
# 格式是 rsync -rvl 源目录/源文件 用户@节点:目标目录/目标文件
rsync -rvl $pdir/$fname $user@$host:$pdir/$fname
从SCP和 rsync的命令使用上看,如果手动拷贝,需要编写多条命令,需要注意每次安装的目录路径和拷贝目标节点和路径。
为了方便,可以编写rsync脚本,并配置为系统命令。方便以后在集群间的拷贝操作。脚本如下
里面需要修改的只是,节点的名字,我这里节点名字就叫做 node<num>。
打开Xshell的发送键到所有节点会话窗口(如果不是Xshell,也可以编写完成后,用scp拷贝到所有的节点上)
3.1- 在/usr/local/bin目录下,编写rsync脚本,名为 rsync-script。
vi /usr/local/bin/rsync-script
#!/bin/bash
#1 获取命令输入参数的个数,如果个数为0,直接退出命令
paramnum=$#
if((paramnum==0)); then
echo no params;
exit;
fi
#2 根据传入参数获取文件名称
p1=$1
file_name=`basename $p1`
echo fname=$file_name
#3 获取输入参数的绝对路径
pdir=`cd -P $(dirname $p1); pwd`
echo pdir=$pdir
#4 获取用户名称
user=`whoami`
#5 循环执行rsync
for((host=121; host<124; host++)); do
echo ------------------- node$host --------------
rsync -rvl $pdir/$file_name $user@node$host:$pdir
done
3.2- 修改执行权限
chmod 777 /usr/local/bin/rsync-script
3.3- 使用示例
rsync-script 文件名称, 例如
rsync-script /opt/cluster/server/hadoop-2.9.2
为了方便本地访问 组件安装后的web服务页面访问
在宿主机,一般是windows系统。
1- 编写 C:\Windows\System32\drivers\etc\hosts 文件

2- 编写虚拟机的 IP地址和节点名字(之前设置的静态IP地址和主机名)
我这里是 192.168.186.121 node121
192.168.186.121 node121
192.168.186.122 node122
192.168.186.123 node123
推荐本站淘宝优惠价购买喜欢的宝贝:

本文链接:https://www.hqyman.cn/post/6890.html 非本站原创文章欢迎转载,原创文章需保留本站地址!
打赏

微信支付宝扫一扫,打赏作者吧~
休息一下~~
