
内容预览:
1. vSphere HA 概述
2. vSphere HA 提供的保护级别
3. vSphere HA运行原理
4. vSphere HA 故障支持场景
5. vSphere HA接入控制策略
6. 如何选择vSphere HA 的接入控制策略
7. 配置vSphere HA的基础条件
8. 虚拟机组件保护
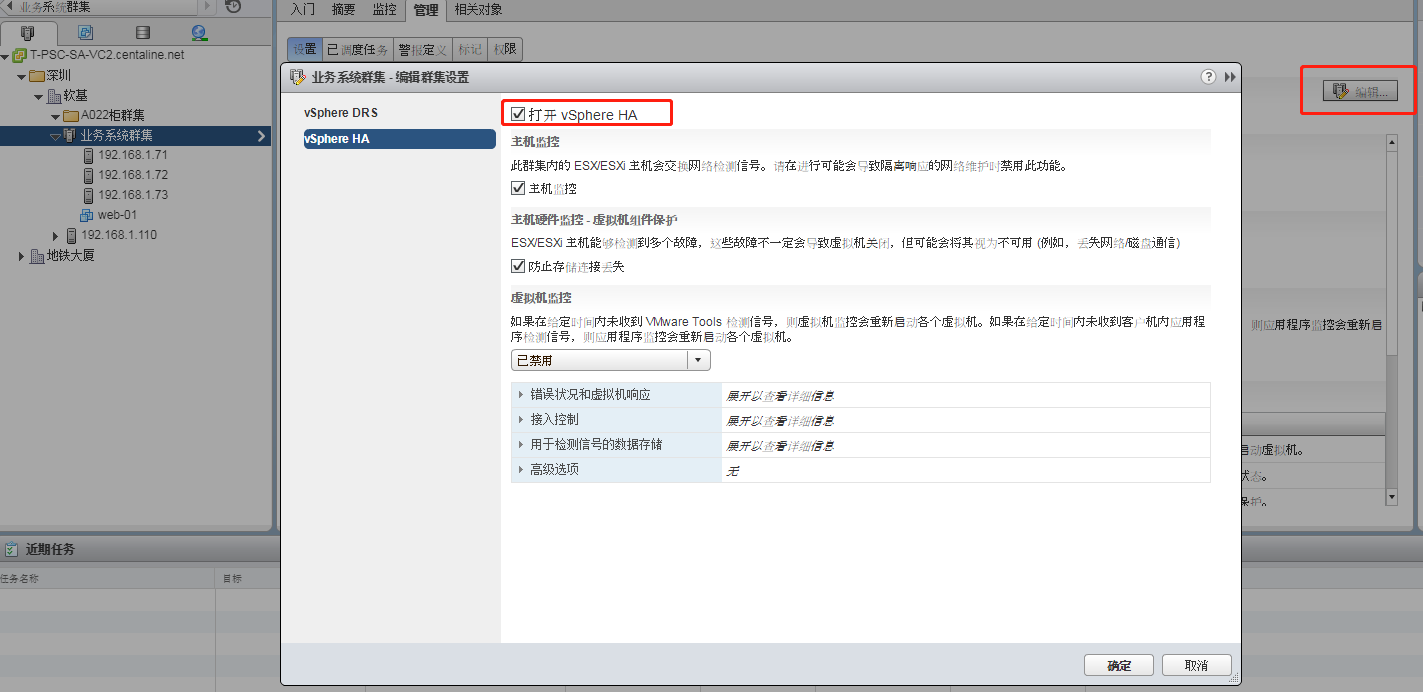
9. 开启vSphere HA功能
HA,High Availability,中文翻译为高可用。
其运行机制是监控群集中的ESXi主机及虚拟机,通过配置合适的策略,当群集中的ESXi主机或虚拟机发生故障,可以自动到其他的ESXi主机上进行重新启动,最大限度保证重要服务不中断。
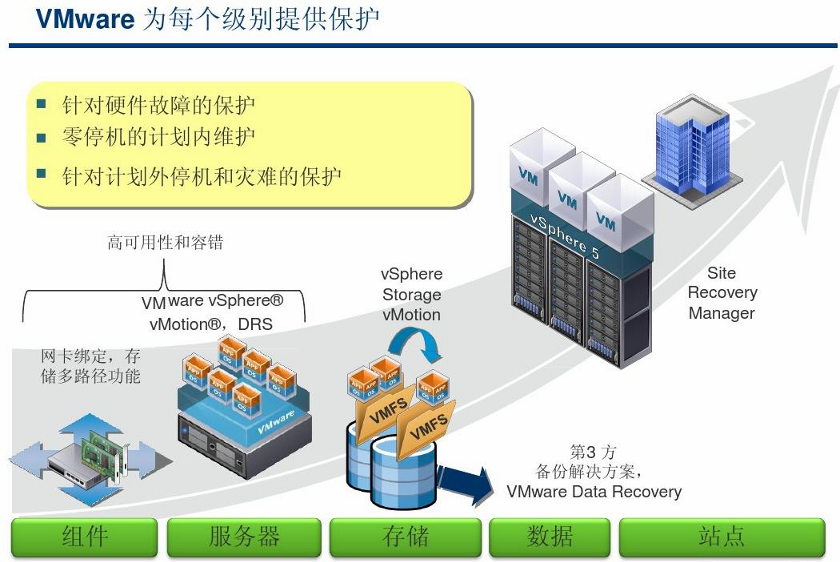
2.1 针对ESXi主机硬件故障的保护(HA和FT技术)
2.2 针对零停机计划内的维护(vMotion)
2.3 针对ESXi主机计划外停机和灾难的保护(HA和FT技术)
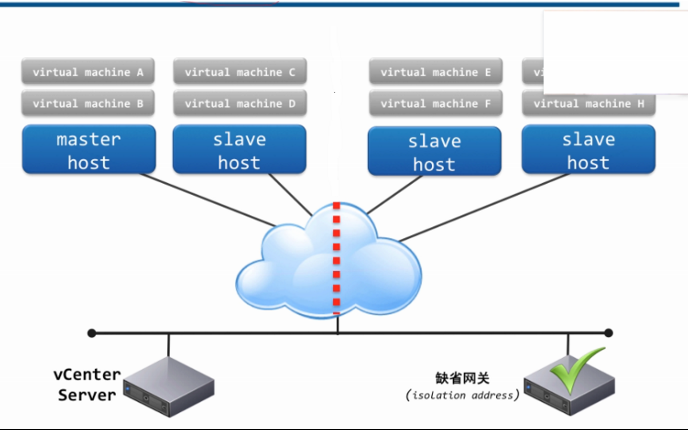
3.1. HA运行的基本原理
当在群集启用HA时,系统会自动选举一台ESXi主机作为首选主机(也称为Master主机),其余的ESXi主机作为从属主机(也称为Slave主机)。Master主机与vCenter Server进行通信,并监控所有受保护的从属主机(也称为Slave主机)的状态。Master主机使用管理网络和数据存储检测信号来确定故障的类型。当不同类型的ESXi主机故障时,Master主机检测并相应地处理故障,让虚拟机重新启动。当Master主机本身出现故障时,Slave主机会重新选举产生Master主机。
3.2. Master/Slave选举机制
3.2.1). Master/Slave主机的选举是存储最多的ESXi主机,如果ESXi主机的存储相同时,会使用MOID(Managed Objective ID,数值大的为Master,)来进行选举。当Master主机产生后,会通告给其他Slave主机。当选举产生的Master主机故障时,会重新选举产生新的Master主机
3.2.2). Master主机监控所有Slave主机,当Slave主机出现故障时重启启动虚拟机
3.2.3). Master主机监控所有被保护虚拟机的电源状态,如果被保护的虚拟机出现故障,将重启虚拟机
3.2.4). Master主机发送心跳信息给Slave主机,让Slave主机知道Master的存在
3.2.5). Master主机执行状态信息给vCenter Server,vCenter Server正常情况下只和Master主机通信
3.2.6). Slave主机监视本地运行的虚拟机状态,把这些虚拟机运行状态的显著变化发送给Master主机
3.2.7). Slave主机监控Master主机的健康状态,如果Master主机出现故障,Slave主机将参与与Master主机的选举
3.3. Esxi主机的故障类型
3.3.1) 主机停止运行
主机由于物理硬件故障或电源等原因引起故障
3.3.2) 主机与网络隔离
一个或多个slave丢失了所有的管理网络连接,这样的slave既不能联系到master也不能联系到其他ESXi hosts。这种情况下,slave主机通过存储网络来通知master,它已经是隔离状态。
我们知道HA使用管理网络及存储设备进行通信监测状态,如果Master主机不能通过管理网络与Slave主机通信,那么会通过存储来确认ESXi主机是否存活,这样的机制可以让HA判断主机是否处于网络隔离状态。在这种情况下,Slave主机通过heartbeat datastores来通知Master主机它已经是隔离状态,具体上这个Slave是通过一个特殊的二进制文件--host-Xpoweron,来通知Master主机能够采取适当的措施来确保保护虚拟机。Master主机看到这个标志后,就知道Slave主机已经是隔离状态,然后Master主机通过HA锁定其他文件(datastores上的其他文件),当Slave主机看到这些文件已经被锁定,就知道Master主机正在重新启动虚拟机,然后Slave主机可以执行配置过的隔离响应动作(如关机或者关闭电源)
3.3.3) 主机与网络分区
一个或多个slave通过管理网络联系不到master,这样的slave虽不能联系到master但能联系到其他ESXi hosts,这种情况下,vSphere HA能够了使用存储网络来检测分离的主机是否存活以及否要保护它们里面的虚拟机。
3.4. ESXi主机故障的响应方式
3.4.1) 虚拟机重新启动优先级
3.4.2) 主机隔离响应
4.1. esxi host 物理服务器故障
4.2. 虚拟机故障
4.3. 虚拟机操作系统故障
4.4. Application 故障
5.1. 按插槽及插槽大小
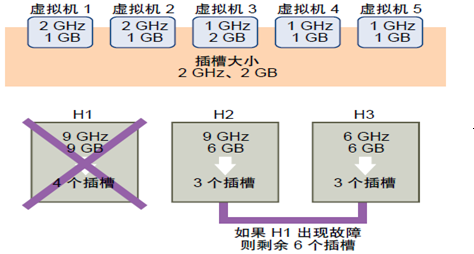
5.1.1). 插槽大小由每个虚拟机的CPU和内存决定,取CPU和内存的需求最大值,通过上图虚拟机可以得知插槽大小为2GHz CPU和2GB内存。
5.1.2). HA计算CPU组件的方法是先获取每台已打开电源虚拟机的CPU预留,如果没有为虚拟机指定CPU预留,则系统会为其分配一个默认值32MHz。
5.1.3). HA计算内存组件的方法是先获取每台已打开电源虚拟机的内存预留,如果没有为虚拟机指定内存预留,则系统会为其分配一个默认值。
5.1.4). 插槽计算:用主机的CPU资源数除以插槽大小的CPU组件,然后将结果化整。对主机内存资源数进行同样的计算。然后,比较这两个数字,较小的那个数字即为主机可以支持的插槽数。
5.2 接入控制策略--按静态主机数量定义故障切换容量
所谓按静态主机数量定义故障切换容量策略,就是允许HA群集中几台ESXi主机可以发生故障,如果设置为1,当群集中有1台ESXi主机发生故障时,故障ESXi主机上的虚拟机会重新启动。同时这个策略需要使用插槽及插槽大小的概念。
5.3 接入控制策略--通过预留一定百分比的群集资源来定义故障切换容量
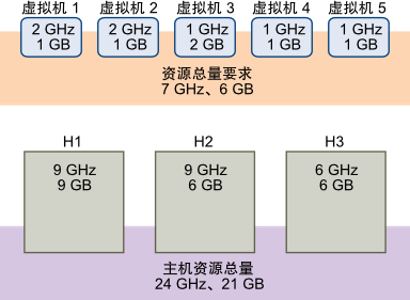
5.3.1). 计算出主机的CPU和内存资源总和,从而得出虚拟机可使用的主机资源总数。
5.3.2). 生产环境需要注意的是,预留资源越多,ESXi主机在非故障切换时能够运行的虚拟机就会减少。
5.4 接入控制策略--使用指定故障切换主机
4.4.1). 在主机发生故障时,vSphere HA 将尝试在任一指定的故障切换主机上重新启动其虚拟机。如果不能使用此方法(例如,故障切换主机发生故障或者资源不足时),则 vSphere HA 会尝试在群集内的其他主机上重新启动这些虚拟机。
4.4.2). 为了确保故障切换主机上拥有可用的空闲容量,将阻止您打开虚拟机电源或使用 vMotion 将虚拟机迁移到故障切换主机。而且,为了保持负载平衡,DRS 也不会使用故障切换主机。
选择接入控制策略时,应当考虑的因素很多。应当基于可用性需求和群集的特性选择 vSphere HA 接入控制策略。
6.1) 选择什么样的接入控制策略?
生产环境比较常见的是选择按静态主机数量定义故障切换容量、预留一定百分比的群集资源来定义故障切换容量这两种策略。
选择前者的话,如果群集中某一台虚拟机所需的CPU或内存资源较大(3,3),而其他虚拟机所需的CPU或内存资源比较平均,会影响到ESXi主机支持的插槽数量计算。
因此,如果群集中虚拟机所需的CPU和内存资源差距较大,推荐使用使用预留一定百分比的群集资源来定义故障切换容量策略。
6.2) 避免资源碎片
“群集资源的百分比”策略不解决资源碎片问题。
通过将插槽定义为虚拟机最大预留值,“群集允许的主机故障数目”策略的默认配置可避免资源碎片。
使用“指定故障切换主机”策略不会出现资源碎片,因为该策略会为故障切换预留主机。
6.3) 故障切换资源预留的灵活性
为故障切换保护预留群集资源时,接入控制策略所提供的控制粒度会有所不同。“群集允许的主机故障数目”策略允许设置多个主机作为故障切换级别。“群集资源的百分比”策略最多允许指定 100% 的群集 CPU 或内存资源用于故障切换。通过“指定故障切换主机”策略可以指定一组故障切换主机。
6.4) 群集的异构性
从虚拟机资源预留和主机总资源容量方面而言,群集可以异构。在异构群集内,“群集允许的主机故障数目”策略可能过于保守,因为在定义插槽大小时它仅考虑最大虚拟机预留,而在计算当前故障切换容量时也假设最大主机发生故障。其他两个接入控制策略不受群集异构性影响。
7.1) vCenter Server
HA这个高级特性必须依赖于vCenter Server才能实现,没有vCenter Server将无法启用HA
7.2) 启用vMotion
当ESXi主机发生故障时,HA会选择新的ESXi主机对虚拟机进行重新启动, 这个过程实质是迁移主机,而迁移主机使用的技术是vMotion,也就是说启用vMotion是前提。
7.3) 网络冗余
HA本身要求网络具有冗余功能,特别是管理网络,如果管理网络没有冗余,HA会给出对应的配置错误提示。
7.4) 安装VMware Tools
它不仅是添加了虚拟机的驱动程序,一些HA的检测机制也是通过VMware Tools完成的。
7.5) 群集ESXi主机数量
将多台ESXi主机添加到一个群集的目的,是可以统一管理及使用高级特性。但是每台ESXi主机的资源是有限的,必须合适考虑群集中ESXi主机的数量,特别是这个群集中ESXi主机数量少于5台,而运行的虚拟机数量超过50台的情况需要特别注意。
当某台ESXi主机发生物理故障,上面的虚拟机需要在其他ESXi主机上重新启动时,要考虑其他ESXi主机资源使用情况。如果资源不够,可能会导致虚拟机无法重新启动,或启动后性能较低。
8.1) 如果启用虚拟机组件保护(VMCP),vSphere HA可以检测到数据存储可访问性故障,并为受影响的虚拟机提供自动恢复。
当发生数据存储可访问性故障时,受影响的主机无法再访问特定数据存储的存储路径,可确定vSphere HA将对此类故障作出的响应,从创建事件警报到虚拟机在其他主机上重新启动。
8.2) 错误状况和虚拟机响应选项
8.2.1) 虚拟机重新启动优先级
重新启动优先级用于确定主机发生故障或主机隔离时虚拟机的重新启动顺序。优先级较高的虚拟机将首先启动。
8.2.2) 针对主机隔离的响应
主机内的虚拟机将在正常运行的其他主机上重新启动
8.3) 存在两种类型的数据存储可访问性故障
8.3.1) PDL(permanent device loss 永久设备丢失):是在存储设备报告主机无法再访问数据存储时发生的不可恢复的可访问性丢失,如果不关闭虚拟机的电源,此状况将无法恢复。
8.3.2) APD(All-Paths-Down 全部路径异常):暂时性或未知的可访问性丢失,或I/O处理中的任何其他未识别的延迟,此类型的可访问性问题是可恢复的。
a). 关闭虚拟机电源再重新启动虚拟机(保守):
受影响的Vms会被关闭电源,然后在连接正常的ESXi主机上重启。如果故障主机无法与Master主机通讯则将无法激活
b). 关闭虚拟机电源再重新启动虚拟机(积极):
受影响的Vms会被关闭电源,无论是否有主机可以通过重启承载这些Vms。不论Master主机是否存在,是否能和其它主机通讯以及是否有足够的资源
8.3.3) APD 的虚拟机故障切换延迟:140S以后
8.4) VMCP恢复时间轴
8.4.1) 以下时间轴以图形方式显示VMCP如何从存储故障进行恢复
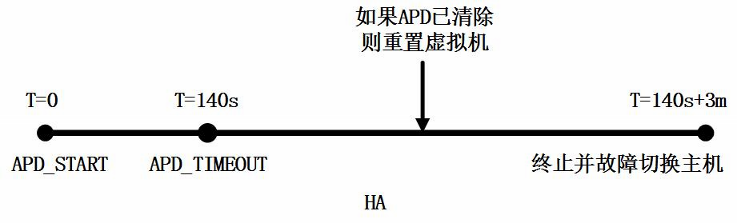
► T=0;检测到存储故障,vSphere HA将启动恢复过程。对于PDL事件,将立即启动工作流并重新启动群集中正常主机上的虚拟机。如果是APD事件导致存储丢失。APD超时定时器将启动(默认为140秒)。
► T=140s:主机将声明APD超时,到无响应存储设备的非虚拟机I/O都将失败。
► 介于T=140s和320s之间:这是APD的虚拟机故障延迟定义的时间段,默认为3分钟,长时间无法访问存储可能导致客户机应用程序不稳定,如果此时间段的APD己清除,重置虚拟机的选项将可用。
► T=320s:经过APD的虚拟机故障切换延迟时间(APD超时后3分钟)后,vSphere HA将启动APD恢复响应。
8.5) 虚拟机监控敏感度:
8.5.1) 故障时间间隔(30S):如果在30S的时间间隔内未收到主机与虚拟机间的检测信号,vSphere HA会重新启动虚拟机。
8.5.2) 最短正常运行时间(120S):发现故障后,不会立即重启虚拟机,先进行120S的和存储I/O的信息监测,以免故障误判。das.iostatsinterval
8.5.3) 每个虚拟机的最大重置次数(3次)
为了避免因非瞬态错误而反复重置虚拟机,默认情况下,在某个可配置的时间间隔内将对虚拟机仅重置三次,在对虚拟机执行过三次重置后,指定的时间结束之前,vSphere HA 不会在后续故障出现后进一步尝试重置虚拟机,可以使用每个虚拟机的最大重置次数自定义设置来配置重置次数。
8.5.4) 最大重置时间段(1小时)
推荐本站淘宝优惠价购买喜欢的宝贝:

本文链接:https://www.hqyman.cn/post/6415.html 非本站原创文章欢迎转载,原创文章需保留本站地址!

 微信支付宝扫一扫,打赏作者吧~
微信支付宝扫一扫,打赏作者吧~休息一下~~