
去几年,中国一直在大力投资于国产微处理器。Phytium 的 D2000 是国产设计的一个例子,我们将在本文中仔细研究它。
Phytium D2000 由八个 FTC663 ARM 内核组成,运行速度为 2.3GHz,以每个内核两个的集群排列。该芯片的目标是台式机、笔记本电脑和工业应用,鉴于其规格,这有点奇怪。但是为了正确评估这一设计,我们必须清楚地了解其设计背后的背景。它不是为了与 AMD 和英特尔能提供的最好的东西正面交锋。它的目的是让中国继续前进,以防他们严重惹恼了一批国家,而这些国家恰好是制造世界上大多数高端芯片的国家。
一般性能
当我们报道金海湾(Golden Cove)、格雷斯蒙特(Gracemont)和其他桌面架构时,我们关注的是架构而不是绝对性能。其他媒体已经在宏观基准测试方面做得很好,所以读者在阅读我们的作品时,已经对一个架构相对于其同行的表现有了很好的了解。不过 Phytium D2000 的情况有所不同。我们不知道其他地方是否有完整的基准评测,所以我们将绕道而行,运行一些工作负载,并提供关于 D2000 情况的背景。请记住,这些结果并不直接与我们过去的结果相比较,因为我们这次是在裸机 Linux 上运行一切。
| Description | Memory Setup | |
| Phytium D2000 | 8x 2.3 GHz FTC663 cores on 14 nm | Single Channel DDR4-2400 |
| Graviton 1 | 16x 2.3 GHz Cortex A72 cores on 16 nm. 8 core cloud instance used | Unspecified DDR4 |
| Ampere Altra | 80x 3 GHz Neoverse N1 cores on TSMC 7 nm. 4 core cloud instance used | Unspecified DDR4 |
| Intel Core i5-6600K | 4x 3.6 GHz Skylake cores on Intel 14 nm | Dual Channel DDR4-2133 CL15 |
由于 Phytium 的目标市场包括台式机,我们将包括英特尔的 Core i5-6600K。这款基于 Skylake 的芯片代表了 2015 年的中端台式机 CPU。由于采用了过时的架构,只有四个核心,以及 3.6 GHz 的全核心提升时钟,它很容易被今天的台式机 CPU 打乱。但就其本身而言,它仍然是一个非常可用的平台,对广泛的桌面应用有合理的响应。
7-Zip
首先,让我们看一下 7-Zip 的文件压缩性能。我们只是简单地计时压缩一个大文件需要多长时间,而不是使用内置的基准。7-Zip 的基准模式将加载尽可能多的内核,但是随着内核数量的增加,压缩单个文件的规模不会太大。在指令组合方面,7-Zip 是一个非常分支的工作负载,几乎完全由标量整数指令组成。它也有一个小的指令足迹,适合大多数 L1 指令缓存,并享有一个高的微操作缓存命中率。
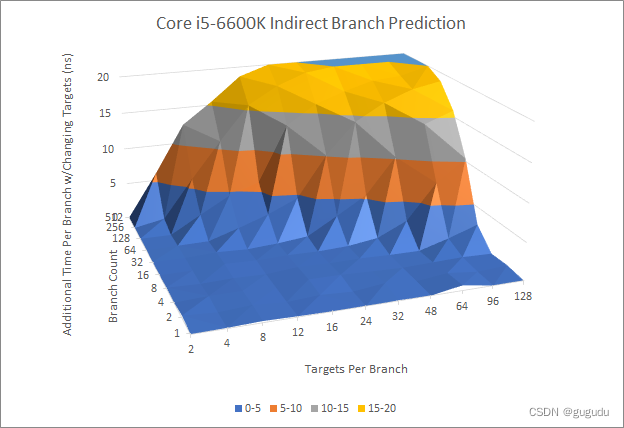
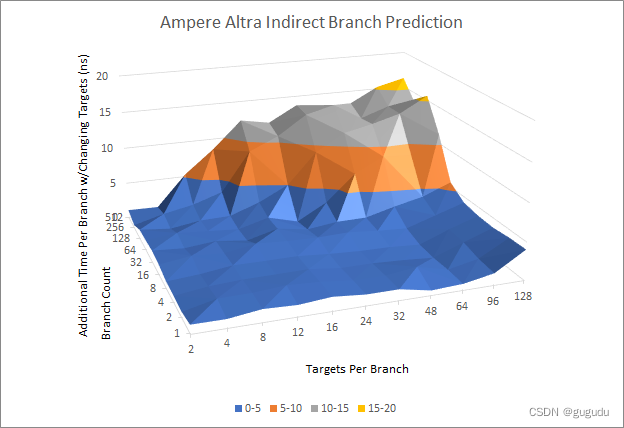








Skylake和N1进行比较。
调用和返回对是间接分支的一个特例,因为返回通常会返回到相应的调用来源处。出于这个原因,CPU 通常用一个特殊的返回栈来预测返回。与 A72 一样,Phytium 的返回堆栈似乎具有与 A72 相同的 31 个条目容量,与 Neoverse N1 的相匹配。Skylake 有一个较小的 16 个条目的返回堆栈,但如果面对溢出其返回堆栈的深度嵌套调用,可以回落到其间接预测器。
总之,FTC663 的分支预测器是相当糟糕的。Skylake 的预测器与 2013 年的 Haswell 预测器相比几乎没有变化,但在每个指标上都超过了它。在 Skylake 时代,ARM 的 Cortex A72 有一个相当平庸的预测器。但是 ARM 从那时起已经走过了很长的路,Neoverse N1 享有一个快速、准确的预测器,也打败了 Phytium 的东西。我还想谈谈 AMD 和英特尔最新架构中的预测器,但转念一想,在这篇 Phytium 文章中这样做简直太卑鄙了。
前端:代码获取带宽
接下来,让我们看看 Phytium 的前端能以多快的速度将指令带入内核——也就是说,只要它不被分支预测器误导或停滞。FTC663 似乎有一个 48KB 的 L1 指令缓存,就像 Cortex A72 一样。该核心有一个 3 宽的解码器,但就像 A72 一样,它每个周期只能解码一个 NOP。NOP 是最简单的指令(它代表 No OPeration),所以这有点奇怪。为了解决这个问题,我们使用了 A72 和 FTC663 的指令带宽测试的修改版,使用了 NOP 和 mov x0, 0 的混合。
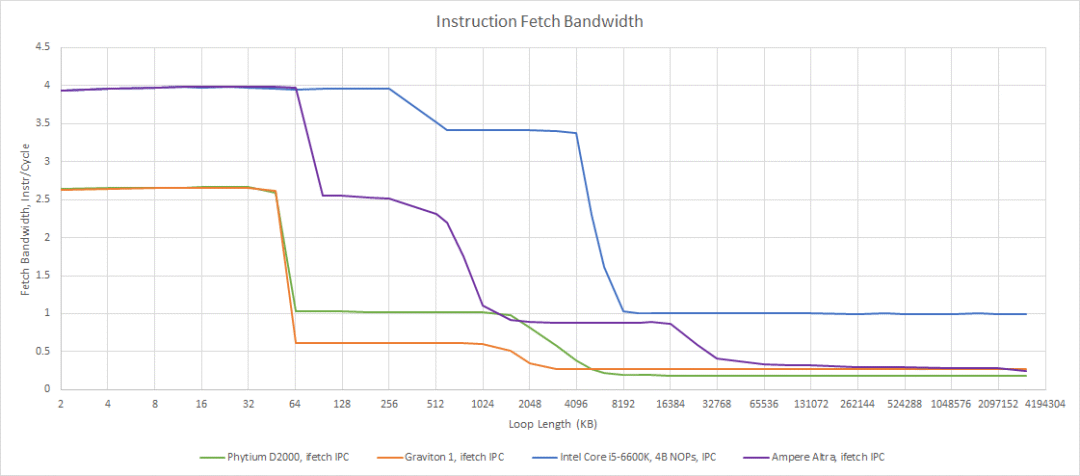
FTC663 和 A72 在从 L2 获取代码时,指令吞吐量都急剧下降,尽管 FTC663 做得更好一些。有趣的是,Phytium 核心在从 L2 运行代码时几乎完全保持了 1 的 IPC。如果 Phytium 使用像 A72 那样的预编码方案,也许预编码机制每个周期只能处理一条指令。
Neoverse N1 和 Skylake 在其整个缓存层次结构中都享有优越的指令侧带宽。N1 可以从 L2 为其核心提供的速度几乎与 Phytium 从其 L1i 提供的速度相同。而 Skylake 可以从其 L3 维持更高的指令带宽。ARM 和英特尔的现代架构也享有更高的缓存容量。结合他们的解耦 BTBs,N1 和 Skylake 可以期望保持相当高的 IPC,即使代码从他们的指令缓存中溢出。相比之下,FTC663 在这种情况下将难以自食其力。
重命名/分配阶段的优化
许多现代 CPU 可以在某些指令被发送到执行引擎时对其进行优化,允许它提取更多的 IPC 或减少执行管道的负载。FTC663 和 Cortex A72 一样,没有做这些事情。在帮助后端方面,除了你在计算机科学课上学到的基本的寄存器重命名的东西外,它没有做任何事情。
| FTC663 IPC | A72 IPC | Neoverse N1 IPC | Skylake IPC | |
| Dependent register to register MOVs | 1.00 | 1.00 | 1.38 | 1.65 |
| Independent register to register MOVs | 1.91 | 1.91 | 2.86 | 3.81 |
| Zero register by XOR/EOR-ing it with itself | 1.00 | 1.00 | 1.00 | 3.81 |
| Zero register by moving an immediate value of 0 into it | 1.90 | 1.91 | 3.61 | 3.82 |
| Zero register by subtracting it from itself | 1.00 | 1.00 | 1.00 | 3.81 |
Skylake的性能计数器显示,sub r,r 和 xor r,r 的情况被消除了,没有任何操作被发送到 ALU 管道。
相比之下,Neoverse N1 和 Skylake 都提供某种形式的移动消除。它们还可以消除某些总是给出零结果的操作,减少 ALU 管道的负载。
乱序执行引擎
乱序执行让 CPU 避免卡在长延迟指令上。为了做到这一点,CPU 的后端有队列和缓冲区,在顺序提交结果之前跟踪处于不同执行阶段的指令。FTC663 的执行引擎看起来像是 Cortex A72 的加强版。它的缓冲区大小适中,在某些方面可与 Neoverse N1 相媲美,但总体上与 Skylake 相比还有差距。
| Structure | Applies To | FTC663 | Cortex A72 | Skylake | Neoverse N1 |
| Reorder Buffer | All instructions pending retirement | 149 | 128 | 224 | 128 |
| Integer Register File | Instructions that write to an integer register | 128 | 96 | 180 | 128 |
| Flags Register File | Instructions that set condition flags (zero, carry, sign, etc) | 26 | 26 | Same as INT RF | 39 |
| FP Register File | Instructions that write to a FP register | 181 | 158 | 168 | 128 |
| 128-bit FP/Vector Register File | Instructions that write to a 128-bit vector register | 47+32 | 31+32 | 168 | 128 |
| Branch Order Buffer | Instructions that could affect control flow | 39 | 39 | 64 | 36 |
| Load Queue | Instructions that read from memory | 32 | 32 | 72 | 56 |
| Store Queue | Instructions that write to memory | 28 | 15 | 56 | 44 |
各种操作的重新排序能力
与 A72 相比,FTC663 在加载、分支和标志设置指令方面具有类似的重排能力。这两款 CPU 也都使用 64 位 FP/矢量寄存器,并分配了其中的多个来处理 128 位 NEON 指令。Phytium 提高了寄存器文件和重排缓冲器的大小,使 FTC663 的重排能力比 A72 提高了一个世代。他们还将 FTC663 的存储队列大小增加到 28 个条目,这比 A72 的 15 个条目的小队列有很大的提升。这些 CPU 每个周期都不能做超过一个存储,使存储队列成为一个相当 "热 "的结构,因为它消耗得很慢。Phytium 通过加强这个队列做出了正确的举动。
但是,一旦任何一个微操作需要一个队列中的条目,CPU 的后端就必须停滞重命名器,所以看看哪些结构的大小没有增加同样重要。
| % of 7-Zip Executed Instructions | % of libx264 Executed Instructions | % of FTC663 ROB | % of A72 ROB | % of Skylake ROB | % of Neoverse N1 ROB | |
| Writes Integer Register (Integer Register File) | 52.34% | 39.74% | 96/149 = 64.4% | 64/128 = 50% | ~154/224 = 68.75% | 88/128 = 68.75% |
| Writes FP/Vector Register File | 0.00001% | 32.08% | 100% (64-bit) 47/149 = 31.5% (128-bit) | 100% (64-bit) 31/128 = 24.2% (128-bit) | 149/224 = 66.5% (128-bit) | 96/128 = 75% (256-bit) |
| Reads from Memory (Load Queue) | 23.66% | 30.4% | 32/149 = 21.4% | 32/128 = 25% | 72/224 = 32.14% | 56/128 = 43.75% |
| Writes to Memory (Store Queue) | 6.89% | 12.79% | 28/149 = 18.79% | 15/128 = 11.7% | 56/224 = 25% | 44/128 = 34.37% |
| Branch | 15.15% | 4.68% | 39/149 = 26.17% | 39/128 = 30.46% | 64/224 = 28.57% | 36/128 = 28.12% |
Phytium 没能纠正 A72 的几个明显的弱点。A72 的负载队列已经有点小了,只占其 ROB 大小的 25%。不难发现,有超过 25% 的指令是从内存中读取的应用。Phytium 没有扩大负载队列的规模,这意味着它可能会在 ROB 或寄存器文件填满之前填满并停滞重命名。他们也没有增加标志寄存器的重命名数量。最后,FTC663 和 A72 一样存在着低效的矢量寄存器分配问题,这意味着矢量寄存器文件会很快填满。有可能 Phytium 将努力利用其增加的重排能力,因为在 A72 上已经有边缘容量的缓冲区变得更加紧张。
Neoverse N1 和 Skylake 对 OoO 资源的分配更加平衡,对各种类型的指令(标量 FP 除外)有更好的 ROB 容量覆盖。因此,它们在实践中会实现更好的重排能力。
与 A72 有更多联系?
FTC663 的乱序引擎做出了一些奇怪的资源分配决定,我们并不经常看到。但相当多的时候,这些特征在 Cortex A72 上也能找到。首先,FP 寄存器文件大到足以覆盖整个重排序缓冲区。通常情况下,CPU 的 FP 寄存器文件与整数寄存器文件的条目数相当。这是因为所有的代码都必须使用整数寄存器来寻址内存和处理控制流,但不是所有的代码都使用浮点寄存器。另外,A72 和 FTC663 的 128 位寄存器分配的效率都很低。每个 128 位的结果要求超过两个 64 位的寄存器,导致 128 位 NEON 代码的重排能力略低。A72 和 FTC663 的设计者可能选择了实现大量的 64 位 FP 寄存器来应对这种寄存器分配的低效率。
FTC663 和 A72 还受到 NOP 重排能力的奇怪限制。NOPs 什么都不做,所以通常你不会期望它们消耗比一个重排缓冲器条目更多的东西,有时甚至不需要。这就是为什么我们通常试图通过观察在 OoO 引擎不能同时处理两个缓存缺失之前,我们可以在长延迟缓存缺失之间放置多少个 NOP 来衡量重排缓冲区的容量。由于我不能理解的原因,A72 和 FTC663 只能重新排序超过 38 个 NOP,尽管它们可以重新排序超过 100 条 FP 指令。更奇怪的是,NOP 在 OoO 引擎中似乎是在消耗一种共享资源。如果我们把 30 个 NOP 放在缓存错过之间,我们用整数寄存器重新排序的能力就会下降到 70 左右(低于 96)。
执行单元
我们没有深入研究详细的指令吞吐量和延迟,但 FTC663 的执行单元似乎与 Cortex A72 的基本相同。两者都具有四个专门的 ALU 管道。两个处理简单的整数运算,一个处理分支,一个处理复杂的整数运算。执行单元在这些管道上的分布很差,因为与其他管道相比,复杂的整数管道可能没有得到充分利用。
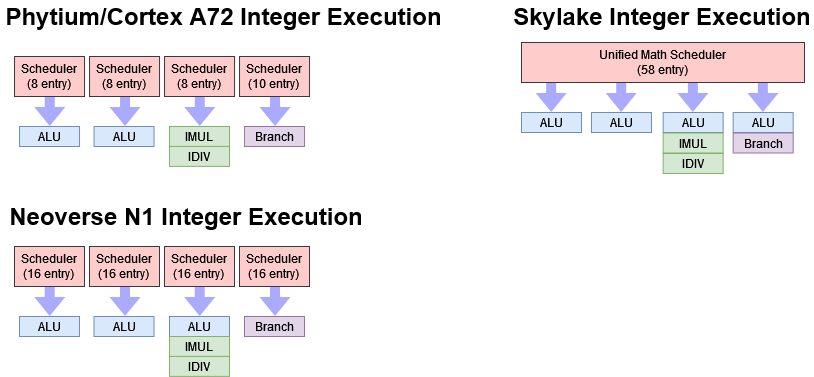
我怀疑整数端口这样设置是为了简化结果总线的调度,而不是增加整数吞吐量。根据 Agner Fog 的说法,当一个执行端口在处理具有不同延迟的指令时,一些 CPU 可能会出现延迟。这是因为执行端口只有一条结果总线,无法处理两条试图同时写回结果的指令。在 A72 和 Phytium 上,这个问题在两个 ALU 管道和分支管道上是可以避免的,因为几乎所有经过它们的指令都会在一个周期内完成。结果总线调度问题将被限制在 "复杂 "的整数管道上。
FTC663 的向量 / FP 执行方面相当薄弱。在我们测试的指令组合中,向量和 FP 执行的吞吐量与 A72 的相同。大多数 FP / 向量执行单元是半宽的(64 位),128 位的操作被发出两次。只有整数 ALU 有 128 位宽度。然而,它们并不像 AMD K8 那样被分成两个微操作,而且只占用一个调度器插槽。考虑到 FTC663 的低时钟速度,浮点和矢量执行延迟是不合格的。
| FTC663 (and A72) Latency | Neoverse N1 Latency | Skylake Latency | |
| FP Add | 4 cycles | 2 cycles | 4 cycles |
| FP Multiply | 4 cycles | 3 cycles | 4 cycles |
| FP Fused Multiply Add | 7 cycles | 4 cycles | 4 cycles |
| 128-bit vector integer add | 3 cycles | 1 cycle | 1 cycle |
| 128-bit vector integer multiply | 4 cycles | 4 cycles | 10 cycles (2×64-bit) 5 cycles (4×32-bit) |
N1 也有两条 FP / 矢量执行管道,但具有全宽的执行单元。在大多数情况下,N1将能够在每个周期完成两条 128 位指令,而 FTC663 只能完成一条。
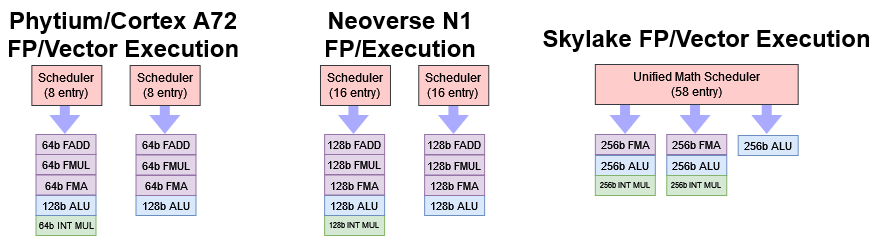
最后,Skylake 拥有非常强大的矢量执行能力,这要归功于全宽执行单元支持的 AVX2。自 Sandy Bridge 以来,英特尔一直是矢量执行性能的领导者,而 Skylake 延续了这个传统。
负载 / 存储执行
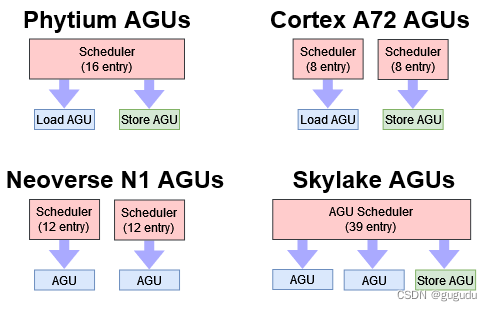
与 A72 一样,FTC663 有两条内存管道,一条用于加载,一条用于存储。然而,Phytium 已经实现了一个统一的 AGU 调度器,它应该比 A72 的分布式调度器更有效率。典型的代码的负载远远多于存储,所以 A72 可能会看到这样的情况:它的负载 AGU 调度器填满了,但存储调度器中还有条目可用。FTC663 避免了这种情况,但仍有有限的内存执行资源,就像 A72 一样。现代高性能内核往往具有更强大的 AGU 设置。例如,ARM 的 Neoverse N1 有两条内存管道,能够同时处理负载和存储。Skylake 有一个更强大的 AGU 设置,可以在每个周期维持两个负载和一个存储。
一旦地址生成,它们就被传递给加载/存储单元(LSU),该单元确保内存操作的正确顺序。与较新的英特尔、AMD 和 ARM CPU 不同,FTC663 的 LSU 不能推测内存操作是否有关联。因此,在知道所有先前的存储地址并可以检查是否有重叠之前,加载操作不能执行。如果有重叠,存储的数据就会被 "转发 "到负载中。存储转发的延迟通常比无争议的 L1D 延迟高一点,Phytium 也不例外。存储转发的延迟是 7 个周期,Phytium 的机制适用于所有存储和负载重叠的情况。与其他 CPU 不同,对于部分负载/存储重叠,没有昂贵的回退路径。唯一的惩罚是,如果负载和存储部分重叠,并且都跨越了 64 字节的缓存线边界,则需要额外的三个周期,或者在某些部分重叠的情况下,需要额外的两个周期来跨越16字节的边界。这两种情况都不是特别昂贵。
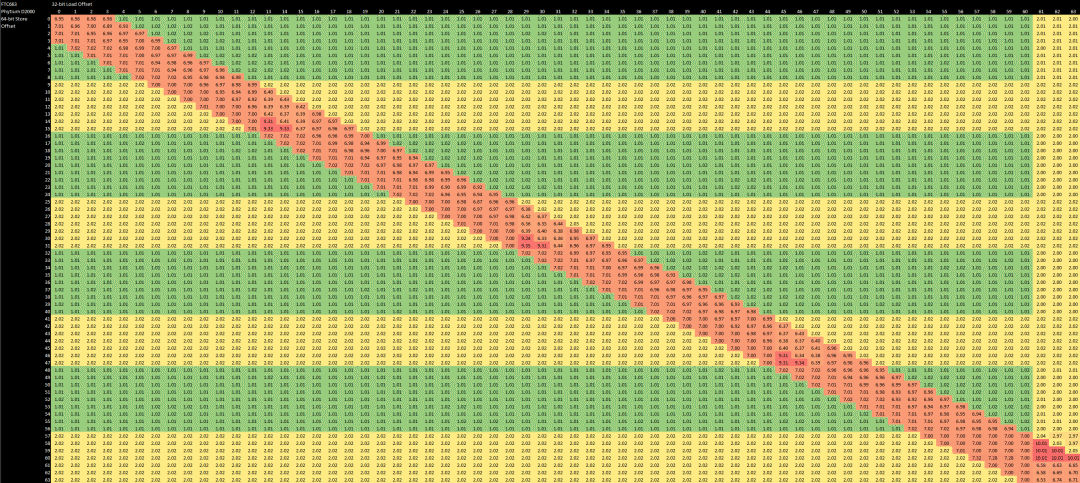
使用 Henry Wong 描述的方法进行存储到加载转发测试(这里只是为ARM编码)。
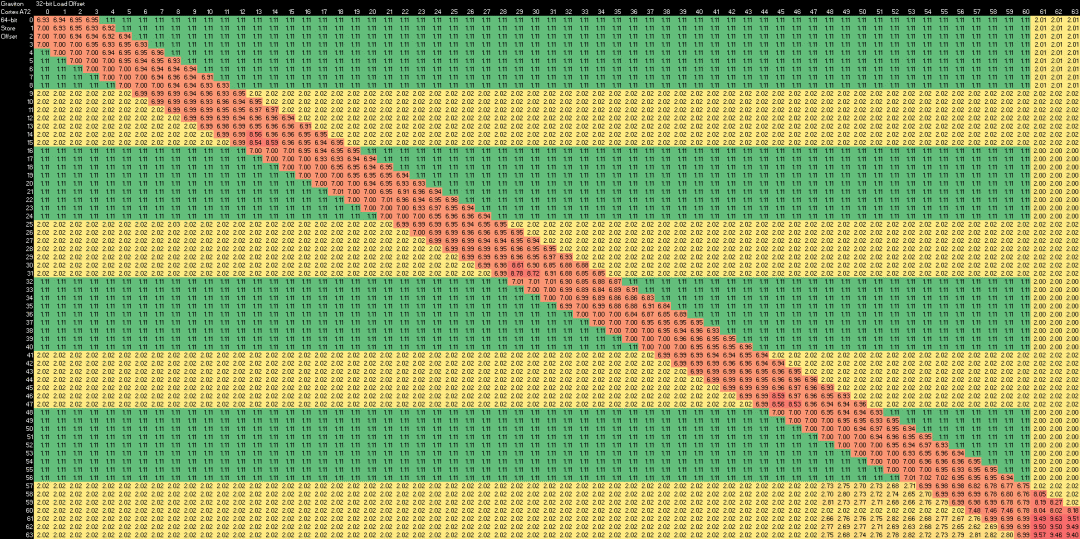
Cortex A72 的结果
总体情况与 A72 类似,尽管 FTC663 通过避免跨越缓存线边界时的一些惩罚而有所改善。在存储转发性能方面,FTC663 和 A72 都比 Neoverse N1 和 Skylake 好,后者在存储和负载部分重叠时受到很大惩罚。

Skylake上的存储到负载的转发
对于独立访问,仍有一些情况会降低 FTC663 的 L1D 吞吐量。如果存储跨越 16 字节的边界,就会花费一个额外的周期,如果加载跨越64字节的缓存线边界,就会花费一个额外的周期。我怀疑 A72 和 FTC663 的 L1D 缓存被划分为 16 个字节的扇区,但是跨越 16B 边界的负载不会受到惩罚,因为缓存有两个读取端口。与 Skylake 和 N1 相比,FTC663 和 A72 更容易受到错位存储的惩罚。
内存访问:延迟
制作一个看起来很酷的核心是一回事,但给它喂食是另一回事。Phytium D2000 有一个三层的内存层次结构。每个内核都有自己的 32KB L1D。每个由两个内核组成的集群有一个 2MB 的二级缓存,整个芯片共享一个 4MB 的三级缓存。L1D 延迟是四个周期,就像 Skylake 和许多其他 CPU 一样。但由于 FTC663 的时钟速度较低,如果能有 3 个周期的 L1D 就更好了。
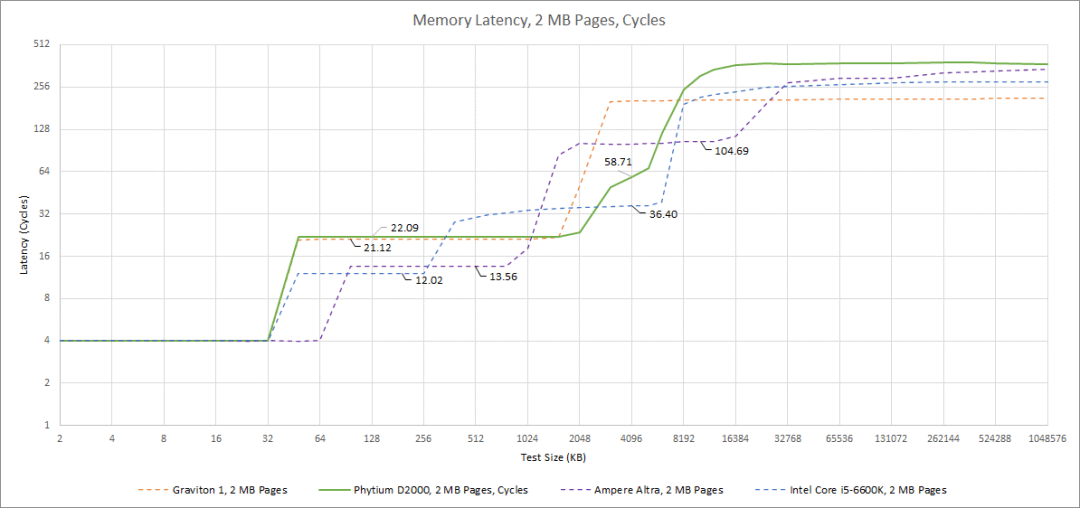
当我们向下移动高速缓存层次时,延迟会迅速下降。FTC663 的共享 L2 缓存有合理的容量,但是需要 22 个周期来访问,这使得它的实际延迟几乎与 Skylake 更大的 L3 相同。当我们到达 L3 时,延迟是可怕的,大约超过 50 个周期。实际延迟超过 20ns,这与 Cascade Lake 的 L3 延迟相似,对客户平台来说不是一个好的表现。至少某种形式的 L3 比没有好。
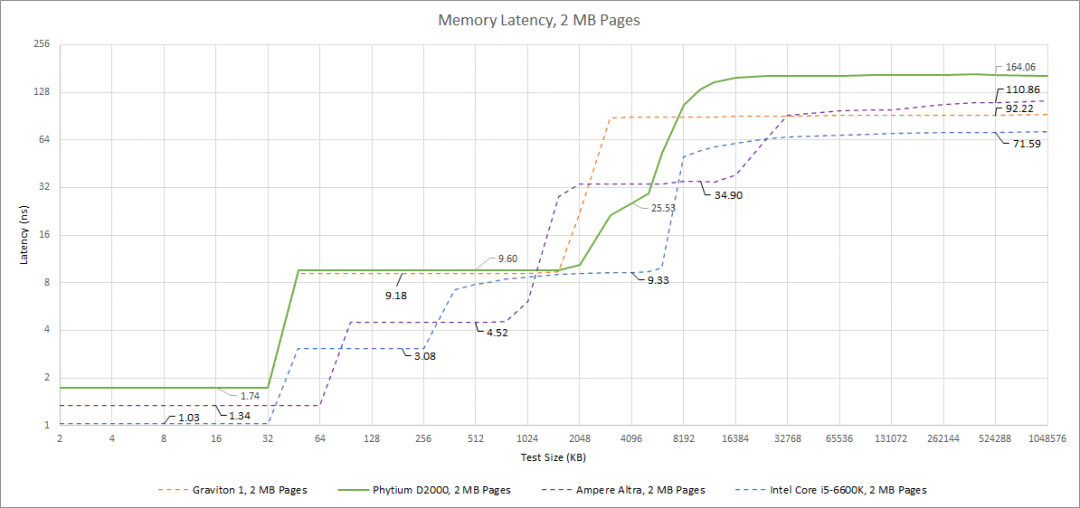
最后,内存延迟是一场灾难,为 164 ns。Phytium D2000 最终遭受的内存延迟比这次比较中的两个服务器芯片都要高。为了显示它有多糟糕,一个双插槽至强 X5650 系统访问远程内存的延迟仅超过 120 ns。这就对了:Westmere 在访问连接在另一个插座上的 DDR3 内存时,仍然能更快地获得它。
4K 页面的内存延时
用 2MB 页面测试内存延迟有助于隔离缓存性能,但大多数客户工作负载使用 4KB 页面。对于 4KB 的页面,TLB 的容量和性能要重要得多。FTC663 和 A72 似乎都有一个 32 个条目的 L1 DTLB,但在 4KB 页的 L1D 容量内都看到了一个奇怪的延迟增加。从上面来看,当使用 2MB 的页面时,这个惩罚就消失了,所以这肯定是某种 TLB 的失误惩罚。
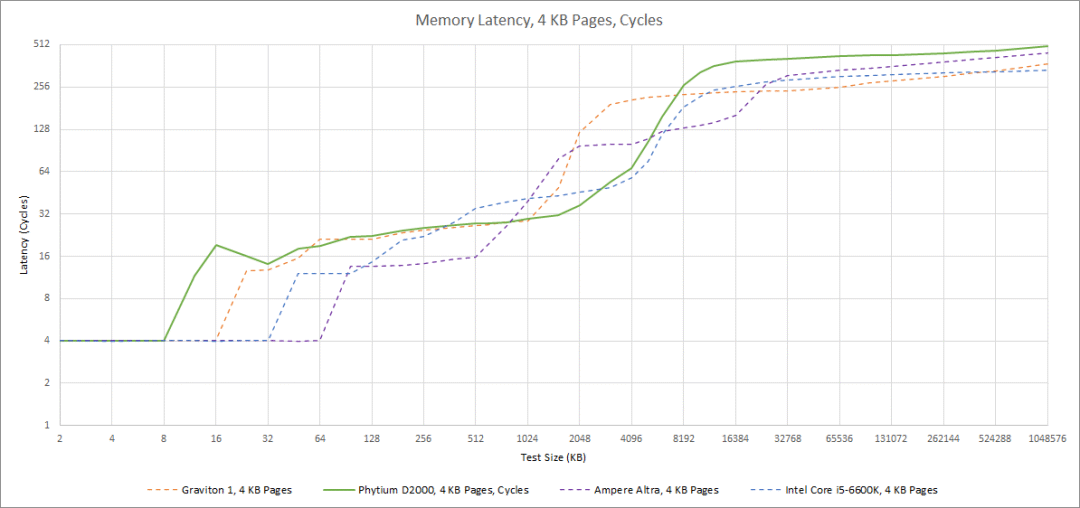
A72 和 FTC663 上的 L2 TLB 比 L1 TLB 命中增加了大约 7 个周期的延迟,而且似乎有大约 1024 个条目的容量。
内存访问:带宽
与 A72 一样,FTC663 的缓存带宽一般都很差。无论如何,矢量性能并不是核心的高优先级,所以我们并不期望看到高缓存带宽。不过,即使在标量整数工作负载中,单负载 AGU 也可能是一个障碍。拥有一个以上负载 AGU 的内核似乎在相当多的周期内发出两个负载操作。
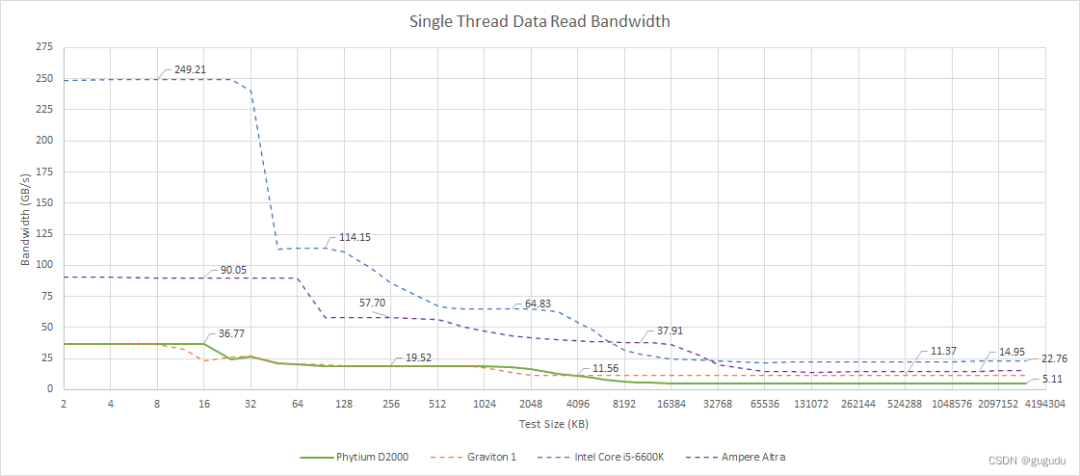
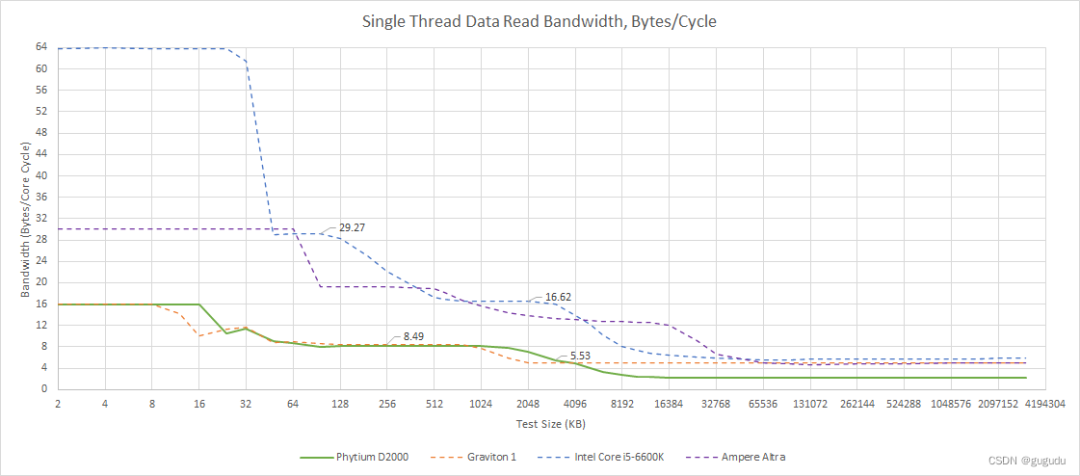
左边是实际带宽,右边是每周期的字节数
Skylake 被设计为矢量工作负载的重灾区,所以它具有大量的高速缓存带宽。N1 的缓存带宽较低,因为它强调的是功率和面积效率而不是矢量性能。尽管如此,N1 仍然远远超过了 FTC663 和 A72,显示了 ARM 自 A72 时代以来的发展。
当我们遇到芯片中的所有线程时,Phytium 的 D2000 缩小了差距,因为我们让它带着八个核心来对付四个 Skylake 或 Neoverse N1 核心。但它只是缩小了一点差距。
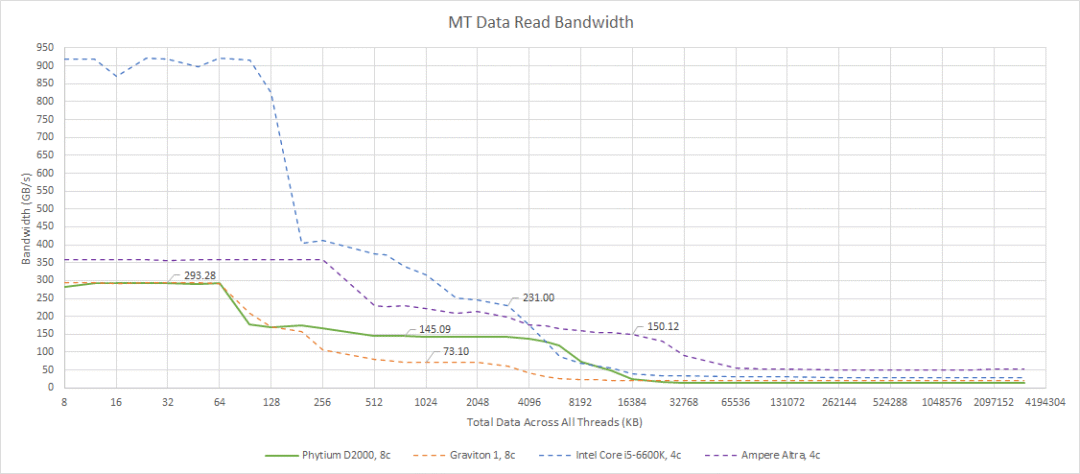
与 Graviton 1 相比,Phytium 的 D2000 看到了改进的二级性能,因为每个二级缓存实例只需要为两个核心提供服务。仔细观察 Graviton 1,Phytium 可能选择了实现双核集群而不是四核集群,因为二级缓存带宽无法扩展到完全满足四个核心。Graviton 1 的 L2 带宽在超过两个线程后就不再扩展了:
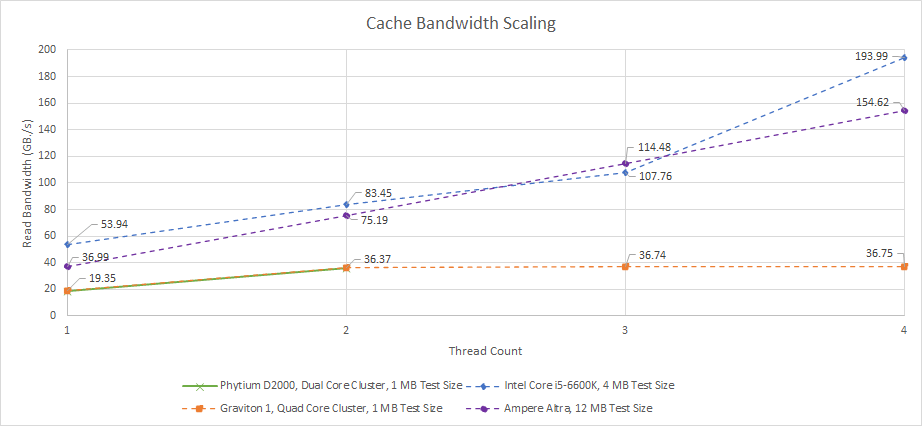
Phytium 可能坚持采用类似的 L2 设计,并选择实现更多的 L2 实例以避免 L2 带宽瓶颈。ARM 和英特尔都采用了更先进的共享高速缓存实现方式,即使用网状或环状互连。缓存片分布在网状或环状挡板上,并允许多线程工作负载有更好的带宽扩展。
拓扑结构,以及核心到核心的延时
如前所述,Phytium 的 D2000 使用双核集群。缓存一致性操作在集群内相对较快,但当需要跨越集群边界时就会慢得多。
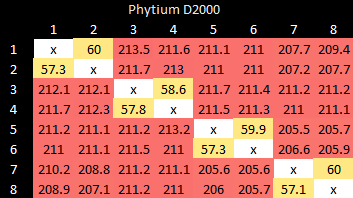
亚马逊的 Graviton 1 看到了类似的延迟,但使用了四核集群。
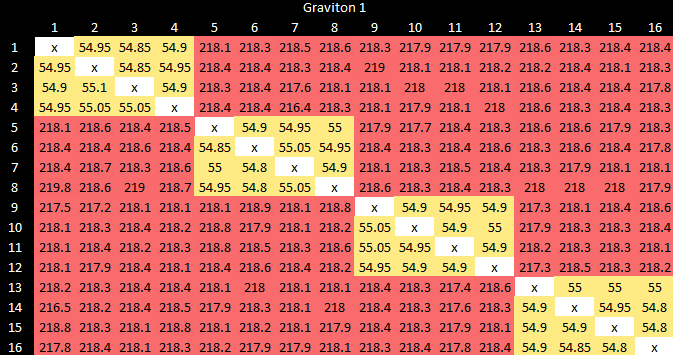
虽然核与核之间的延迟对大多数应用的影响很小,甚至没有影响,但英特尔通过使用环形总线在八核设计中能够实现更好的延迟。
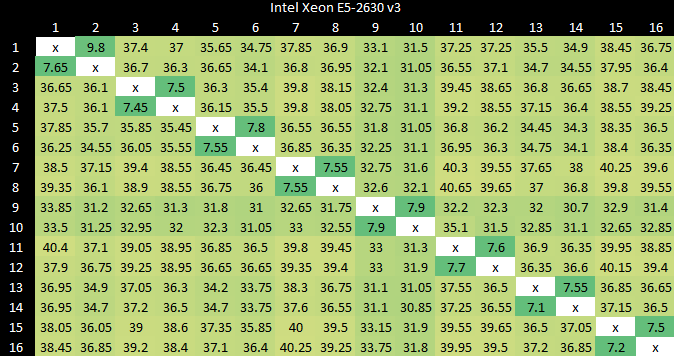
8核 Haswell
AMD 也将核心安排在集群中,但在集群内和集群间都能实现更好的延迟。
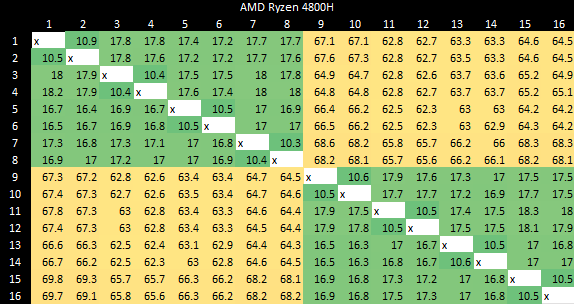
在桌面 Zen 2 上,跨集群的惩罚有点高,但仍然比 Phytium 的低得多。
结论(针对普通消费者)
Phytium 的 D2000 针对桌面、移动和嵌入式市场。也许它对嵌入式用途来说是足够的,但 D2000 在桌面和移动上完全没有竞争力。它在良好的线程负载中被英特尔的 i5-6600K 打败,后者的内核更少,而且在七年多前就进入市场。AMD 和英特尔目前的产品可以不费吹灰之力打败 i5-6600K,所以你可以想象 Phytium 有多落后。
价格对 Phytium 也没有帮助。我们为 D2000 系统支付了 500 多美元。以同样的价格,我们可以建立一个基于八核 Zen 3 的 PC。鉴于这种选择,任何消费者都没有理由考虑 D2000。即使 D2000 的价格大幅下降,也很难想象它在哪里有意义。i5-6600K 在二手市场上的售价约为 50 美元,这并没有给 Phytium 的 D2000 留下太多的空间来压低它。事实上,Phytium 在不亏本销售芯片的情况下可能无法压低 i5 的价格。HKEPC 发布的 Phytium 的幻灯片显示了 132.08 平方毫米的芯片面积,这比 Skylake 的 122.4 平方毫米的芯片要大。
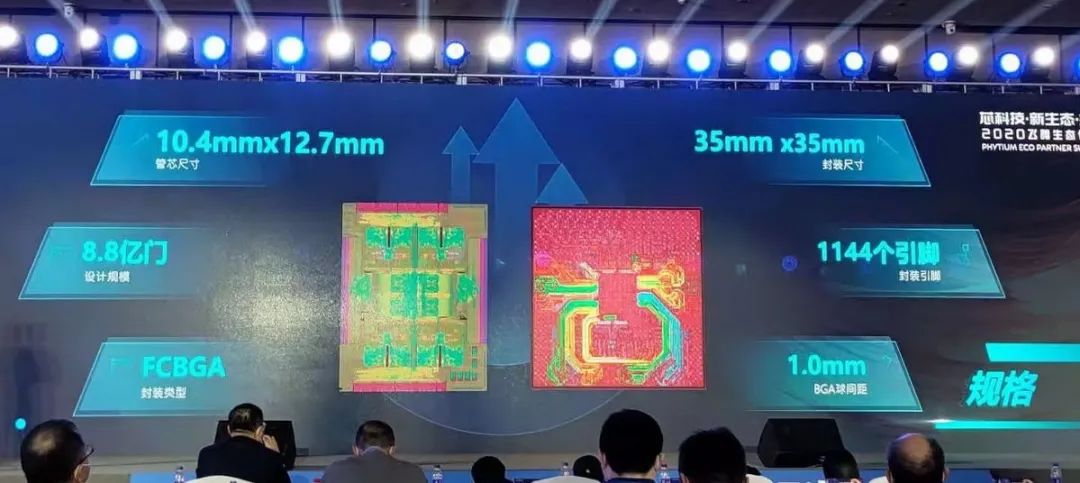
HKEPC 的幻灯片,显示 Phytium D2000 的芯片面积使用情况
如果你想知道 Phytium 的 D2000 是否是你下一个台式机或笔记本电脑的好 CPU 选择,你现在可以停止阅读,因为它肯定不是。
结论(有政治背景):
在短期内,我不认为 D2000 能帮助中国。它的性能即使与十年前的台式机芯片相比也极不具竞争力,以至于中国最好是在垃圾堆中寻找老的英特尔和 AMD 芯片。就我个人而言,我讨厌使用 D2000,即使是用于日常网络浏览,更不用说像照片和视频编辑这样要求更高的使用情况。从二手市场上抢购旧的台式机芯片将花费更少,同时提供更可用的计算体验,并让中国更好地抵御可能的制裁。
另一个角度是,中国正在对芯片生产进行长期投资,而 D2000 代表了一种早期的努力。D2000 预计不会有成本效益,因为芯片制造极其复杂,而且入门成本很高。相反,中国正在为 D2000 这样的产品支付远高于市场价格的费用,以建立国内的专业知识和制造能力。因此,让我们暂时忽略成本和性能竞争力,看看 FTC663 显示了中国在国内芯片设计方面的进展。有几个因素让我对中国未来的努力非常不看好。
首先,我不认为FTC663是一个全新的本土设计。FTC663与A72有太多相似的地方,包括我们在A72上看到的不明显的设计选择和其他地方没有出现的怪癖。列举其中一些:
在我们测试的所有指令组合中,指令吞吐量和延迟都是相同的。除了我们之前列出的,两者都有 5 个周期的整数乘法延迟,而且在给定标量 FP 操作时,两者在使用 FP / 矢量管道方面的效率都很低。
NOP 的吞吐量被限制在每周期 1 个,即使内核是 3 个范围的。
NOPs 在 ROB 条目之外消耗 OoO 资源
128 位指令的向量寄存器分配效率不高
48 KB L1 指令缓存(不是一个常见的大小),带有耦合的 BTB,最大可达到 4096 个分支目标。
当测试大小超过 16KB 时,使用 4KB 页面的 L1D 延迟增加,带宽降低(无法解释的 TLB 惩罚?)
再加上其他的相似之处,如相同的 L1 和 L2 数据侧带宽,匹配的负载队列大小,以及相同数量的标志寄存器重命名,有太多的东西不可能是简单的巧合。例如,Centaur 的 CNS 名义上是一个 Haswell 级的核心,但这两个架构有巨大的内部差异。甚至不同世代的英特尔架构也有比 FTC663 和 A72 更大的差异。
如果 Phytium 没有从头开始开发架构,我们可以通过看他们如何迭代 A72 来评估他们的专业知识。如果他们成功地实现了一代人的性能飞跃,或者将先进的微架构功能带入核心,那么我们可以说中国开始建立一个坚实的知识基础。不幸的是,Phytium 的变化并不代表比 A72 好的迭代。
| FTC663 的变化 | 评论 | |
| 分支预测器,分支方向预测器 | 更长的分支历史,但处理大量分支的能力更差 | 预测器可能在技术上更先进,但调整得很差,在实践中提供更低的预测精度 |
| 指令获取 | 从 L2 获取代码的带宽略微好一点 | 注意到改进,但 L2 代码获取的 BW 仍然远远低于现代内核的 BW |
| AGU 调度器 | 统一的 16 条目调度器,而不是 8+8 | 略有改善 |
| 重排能力 | ROB 容量增加,FP/INT 寄存器数量也增加。存储队列大小增加 | 最大重排能力有了很好的提高,但是太多的关键 OoO 结构没有得到提升。可能影响有限 |
| 负载 / 存储单元 | 在处理重叠的负载和存储时,如果它们都跨越了缓存线的边界,处罚会略微降低。 | 可能是非常小的影响 |
重新排序能力的提升会因为重要结构(即负载队列)的尺寸没有增加而被削弱,这些结构一开始就太小了。L2 代码获取带宽的增加似乎被性能仍然很低的 L2 所抑制。分支预测器的退步削弱了这些改进。如果你最终因为分支预测错误而丢掉了额外的工作,那么你从更远的推测或更快的拉入代码中并没有得到什么好处。
基本上,Phytium 向前走了一步,又后退了一步,同时保留了 A72 的所有基本弱点——ARM(公司)在其后续设计中基本纠正了这些弱点。如果我们看一下 Neoverse N1,它与 A72 简直是天壤之别。当然,N1 并不拥有比 FTC663 更高的最大重排能力。但是 N1 与高性能的英特尔和 AMD 桌面芯片相比,它与 A72 的前身有更多的共同点。它有一个非常准确的分支预测器,通过长距离 BPU 驱动的代码预取进行快速分支处理,有一个低延迟的 L2,可以在有未知地址的存储之前提升负载,以及平衡分配 OoO 资源,这将使它比 FTC663 更好地利用其理论重排序能力。ARM 的工程师没有英特尔的高性能桌面内核所享有的面积或晶体管预算,但他们知道如何将面积 / 晶体管分配到最重要的地方。这就是他们如何使 N1 领先于 FTC663 的原因,这表明 ARM 拥有强大的工程师。
ARM 和 Phytium 似乎在 A72 上有一个共同的起点。然而,ARM 拥有有能力的工程团队,牢牢掌握了设计高性能架构的基本知识,这使他们有能力对其设计进行有意义的迭代。我不能说 Phytium 也是如此,因此我不能说我对他们的长期前景充满热情。不过,看到不同的设计还是很有趣的,而且事情总是可以改变。我们期待着看到 Phytium 在未来的发展。
推荐本站淘宝优惠价购买喜欢的宝贝:

本文链接:https://www.hqyman.cn/post/4529.html 非本站原创文章欢迎转载,原创文章需保留本站地址!

 微信支付宝扫一扫,打赏作者吧~
微信支付宝扫一扫,打赏作者吧~休息一下~~