
在本文系列中,我想谈谈Linux内核中IPv4路由查找以及它产生的路由决策如何确定网络数据包通过网络堆栈的路径。表示路由决策的数据结构被用于网络堆栈的许多部分。它们进一步代表了路由缓存的基础,这有着复杂的历史。因此,了解它们的语义对于理解非常有用。此外,Linux内核实现了许多优化和高级路由功能,这在阅读源代码的这些部分时很容易让你“只见树木不见森林”。本文系列试图缓解这一点。
概述
在先前的文章中,我讨论了路由决策,由外部的struct rtable和内部的struct dst_entry表示,后者作为路由查找的结果附加到网络数据包skb上。然而,我有意遗留了一个非常重要的话题... 缓存。当您查看数据包由于附加的路由决策而如何处理数据包时,了解这个附加决策实际来自哪里并不重要(至少乍一看是不重要的)。也许它是专门为手头的网络数据包分配的,或者它来自某种缓存……这都不重要。结果处理数据包的方式都是一样的。然而,这并不意味着缓存这个话题不那么重要。事实上,它非常重要,特别是在性能方面,由于其复杂的历史,我认为它值得有一篇专门的文章。你可能在各处都听说过路由缓存这个术语,对吧?在早期内核中实际存在一个完整的路由缓存,并在v3.6中被移除。然而,这并不意味着缓存完全消失了。自从那次移除以后,内核中添加了其他关于路由决策的缓存和优化机制。此外,一些已经存在的机制也被保留了下来。互联网上充斥着提到某种路由缓存的文章和文档。然而,由于其丰富的历史,很容易被所有这些部分矛盾的信息弄得困惑。至少在开始时这是我的问题。本文试图对这些信息进行整理,并将旧内核中的情况与像v5.14这样的现代内核中的情况放在上下文中进行说明。
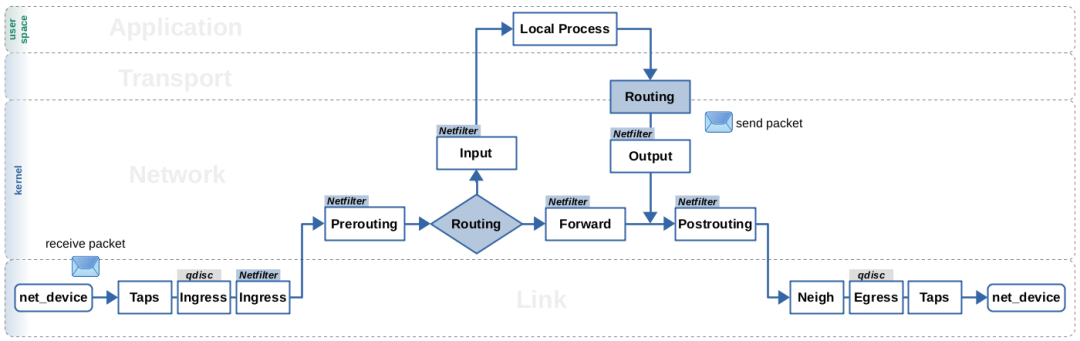 图1:简化概述:路由查找、数据包流动和Netfilter hook
图1:简化概述:路由查找、数据包流动和Netfilter hook
所有这些缓存机制,无论是历史上的还是现代的,有一点是共同的:它们都基于相同的数据结构。这就是为什么struct dst_entry也被称为目的地缓存。然而,当你比较接收路径和本地输出路径时,缓存的工作方式有些不同。这就是为什么我在这里再次展示上一篇文章中的图1。它大致指出了在这两条路径上通常进行路由查找的位置。我强烈建议您先阅读本系列的前一篇文章,以便充分理解接下来我将在各节中解释的内容。
The "old" Routing Cache
在v3.6版本之前的Linux内核中包含一个路由缓存,在实际路由查找之前会先查询该缓存。只有当对该缓存的查找没有产生匹配项时,才会执行实际的路由表查找,包括基于策略的路由。该缓存实现为全局哈希表rt_hash_table。根据所涉及的网络数据包的协议和元数据(如源IP地址和目标IP地址等),构造一个键,对此哈希表进行查找。与本地输出路径相比,接收路径上的细节略有不同。如果缓存匹配成功,则返回一个由外部的struct rtable和其内部的struct dst_entry表示的路由决策实例,然后将其附加到网络数据包(skb)上。如果缓存没有产生匹配,则执行正常的路由查找,由函数fib_lookup()(此功能包括基于策略的路由和对路由表的实际查找)完成。如果该查找产生了匹配的路由,则基于该结果分配和初始化一个新的路由决策实例,然后将其添加到缓存,最后附加到数据包(skb)上。路由缓存实现带有一个垃圾回收器,该回收器基于定期计时器执行,并且在某些事件(例如,当缓存条目数超过特定阈值时)也会触发。
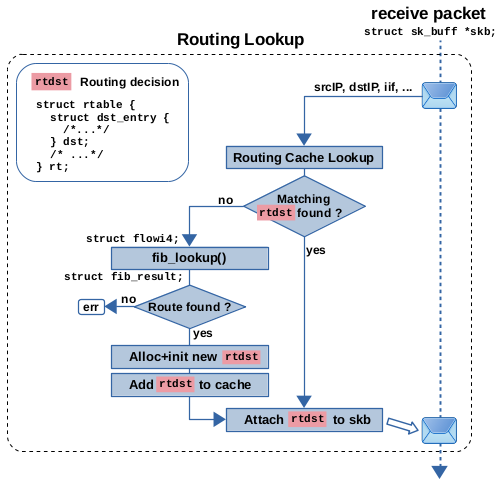 图 2:在 v3.6 之前的内核中,在接收路径上的路由缓存查找和路由表查找
图 2:在 v3.6 之前的内核中,在接收路径上的路由缓存查找和路由表查找
让我们来看一下内核v3.5的源代码,这是在缓存被移除之前的最终版本:图2展示了接收路径上的行为。在那里,函数ip_rcv_finish()调用ip_route_input_noref(),后者又调用ip_route_input_common()。这是缓存查找的实现位置。在接收路径上,用于缓存查找的键是基于数据包的源IP地址和目标IP地址、其入口网络接口索引、IPv4 TOS字段、skb->mark以及网络命名空间。如果命中了缓存,缓存的路由决策对象将附加到网络数据包上,一切都完成了。如果未命中缓存,则调用函数ip_route_input_slow()。它调用fib_lookup(),并根据结果分配和初始化一个路由决策对象。然后,将此对象添加到路由缓存中,然后附加到网络数据包上。现在你知道了,为什么函数ip_route_input_slow()被命名为“slow”了。它只在缓存未命中时调用,并执行完整的路由表查找,包括基于策略的路由。在新版本的内核中,由于缓存被移除,实际上总是会调用该函数,但其名称并未更改。
 图3:在v3.6版本之前的内核中,本地输出路径上的路由缓存查找和路由表查找
图3:在v3.6版本之前的内核中,本地输出路径上的路由缓存查找和路由表查找
现在让我们来看一下内核 v3.5 中的本地输出路径,如图3所示。缓存和路由查找几乎与接收路径相同;然而,有一些细微的差异。与前一篇文章一样,我再次以函数 ip_queue_xmit() 为例,该函数在 TCP 套接字希望在网络上传送数据时使用。它调用 ip_route_output_ports(),后者又调用 ip_route_output_flow(),后者又调用 __ip_route_output_key()。这是缓存查找的实现位置。查找键是根据发送套接字提供的数据生成的,如源和目标 IP 地址、出口网络接口索引、IPv4 TOS 字段、skb->mark 和网络命名空间。显然,要发送的本地生成的数据包没有入口网络接口。因此,这里使用的是出口网络接口。但等一下,出口网络接口实际上不是由路由查找确定的吗?那么,它怎么能成为路由缓存查找的输入参数呢?源 IP 地址也是如此,一旦确定了出口接口,它就会被隐式确定。如果发送此数据包的套接字绑定到特定的网络接口或分配给该系统上其中一个网络接口的 IP 地址,则可以预先确定这两个参数。在所有其他情况下,当然是路由查找本身确定这些参数。好的,让我们回到数据包处理上:在缓存未命中的情况下,将调用函数 ip_route_output_slow(),后者又调用 fib_lookup(),与接收路径相同。然后根据其结果分配和初始化一个路由决策对象,然后将其添加到路由缓存中。但是,无论路由决策对象是刚刚分配的还是来自路由缓存,它附加到网络数据包的处理实际上并不作为整个路由查找的一部分处理。这在函数 ip_queue_xmit() 中的几个函数调用层中发生。现在这可能看起来像是一个无关紧要的细节,但在下面的部分中,你会看到它以后会变得重要。
因此,为什么在 v3.6 中删除了路由缓存呢?它的问题是,它容易受到拒绝服务(DoS)攻击。正如描述的那样,它为每个单独的流缓存了路由决策;因此,大致适用于每个源+目的IP地址对。因此,你可以通过向随机目的地发送数据包轻松地填充缓存条目。当然,删除缓存会带来性能损失,因为现在每次都必须执行完整的路由查找,即 fib_lookup()。然而,在删除之前的几个内核版本中,所谓的 FIB trie算法成为了内核中使用的默认路由表查找算法。这发生在内核 v2.6.39中。该算法提供了更快的查找速度,特别是对于条目数量很多的路由表,从而使删除路由缓存成为可能。以下参考资料提供了有关路由缓存及其删除的进一步详细信息:
Tuning Linux IPv4 route cache (Vincent Bernat, 2011) Removing The Linux Routing Cache (David S. Miller, 2012) Routing cache is dead, now what ? (David S. Miller, 2013)
FIB Nexthop Caching
路由缓存的删除并不意味着在现代内核中完全不会发生路由决策的缓存。相反,这里有几种机制。我在本节中描述的机制可能可以称为在 FIB NextHop 条目中的缓存。这意味着什么?首先,这种机制并不意味着取代正常的路由查找。该查找是以我在上一篇文章中描述的方式进行的。然而,在每次路由查找后都没有必要分配和初始化一个新的路由决策实例。简而言之,如果两次路由查找都产生相同的结果;因此,在两种情况下选择了相同的路由条目(路由),那么这也意味着路由决策对象将具有相同的内容。因此,这种机制大致上为您的路由表中的每个条目缓存一个路由决策对象。只有在第一次使用某个特定路由条目时才分配和初始化新对象。一旦再次使用该条目,就会使用该路由决策的缓存版本,并将其附加到网络数据包上。我故意说“大致上”,因为稍微简化了一些事情,以解释基本原理。例如,不仅需要缓存一个路由决策对象,而且实际上需要缓存两个路由决策对象,因为您需要区分接收路径和本地输出路径;我会解释的。让我们深入一点:如果您查看路由表的条目是如何保存的,那么它并不像使用单个数据结构的实例在内存中保存路由条目那么简单。路由查找是基于FIB trie算法的,并且针对速度和节省内存消耗进行了高度优化。除了LC-trie 本身之外,还涉及到几个数据结构,如 struct fib_info、struct fib_alias、struct fib_nh 和 struct fib_nh_common。如果您使用ip route命令列出路由表的条目,则每个路由条目(每行)的内容实际上是从这些数据结构的多个实例中收集的。唯一的数据结构,其实例似乎与路由条目具有一对一的关系,是struct fib_alias。所有这些数据都以非常节省内存的方式保存,因此,例如,如果两个路由条目的一部分内容恰好相同,则可能只保存一次,而不是两次。这里情况有些复杂。对于缓存而言,重要的是struct fib_nh及其成员struct fib_nh_common。这里的 nh 表示下一跳(nexthop)。因此,这些数据结构的实例保存了描述下一跳的路由条目的部分,比如via 192.168.0.3 dev eth0。在图4中,我使用 ip route 命令的语法展示了一个示例路由表的条目。属于下一跳的条目部分以红色显示。
 图 4:示例路由表;下一跃点数据以红色显示
图 4:示例路由表;下一跃点数据以红色显示
然而,正如我所说的,路由条目与这些下一跳(nexthop)数据结构的实例之间并不一定存在一对一的关系。多个路由条目可以具有相同的下一跳数据,因此这些数据可能只保存在一个实例中。另一方面,在多路径路由的情况下,单个路由条目可以具有多个下一跳实例。然而,数据结构 struct fib_nh_common 具有两个成员变量用于保存路由决策的缓存实例;因此,指向类型为 struct rtable 的指针;参见图5。这些是 nhc_pcpu_rth_output 和 nhc_rth_input。前者是每个 CPU 的数据,用于本地输出路径上的路由查找。后者只是一个单一指针,在接收路径上的路由查找中使用。为接收路径和本地输出路径分别设置缓存是必要的,因为即使路由查找具有相同的结果,结果路由决策包含那些确定网络数据包通过网络堆栈的路径的函数指针 (*input)() 和 (*output)(),还记得吗?正如我在前一篇文章中所描述的,与本地输出路径相比,在接收路径上,这些指针指向不同的函数。
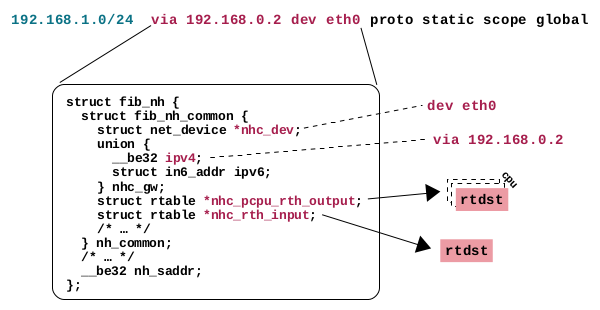
图 5:路由条目中存储在 struct fib_nh_common 中的下一跳数据.其他成员变量用于缓存接收路径和本地输出路径上的路由决策
因此,这是如何使用的呢?假设在接收路径上为网络数据包进行路由查找。这在图6中有所说明。调用函数 ip_route_input_slow()。它准备 flowi4 请求并调用 fib_lookup(),后者以通常的 struct fib_result 形式返回路由查找结果。该结构包含指向匹配路由条目所有部分的指针,包括指向 struct fib_nh_common 实例的指针。如果在此匹配的路由条目是第一次匹配,则成员 nhc_rth_input 的指针仍为 NULL,因此需要分配和初始化一个新的路由决策对象。完成此操作后,nhc_rth_input 被设置为指向该新对象,从而对其进行缓存。然后将对象附加到网络数据包上。因此,当同一路由条目再次匹配另一个网络数据包的查找时,就会使用 nhc_rth_input 中缓存的路由决策对象,并将其附加到该数据包上,无需分配新对象。这在本地接收的数据包以及转发的数据包中都是如此。
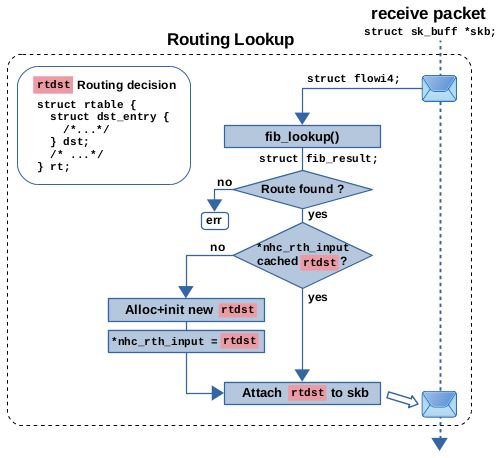 图6:在接收路径上进行路由表查找和下一跳缓存
图6:在接收路径上进行路由表查找和下一跳缓存
现在让我们来看一下本地输出路径上的路由查找。这在图7中有所说明。对于 TCP,会调用函数 __ip_queue_xmit()。它调用 ip_route_output_ports() 进行路由查找。在调用栈的更深层,会调用函数 ip_route_output_key_hash_rcu(),它大致执行与 ip_route_input_slow() 在接收路径上执行的相同操作。唯一不同的是,这里使用 struct fib_nh_common 成员 *nhc_pcpu_rth_output 进行缓存,并且将路由决策对象实际附加到网络数据包的操作发生在调用函数 __ip_queue_xmit() 内部,而不是在路由查找处理函数内部。
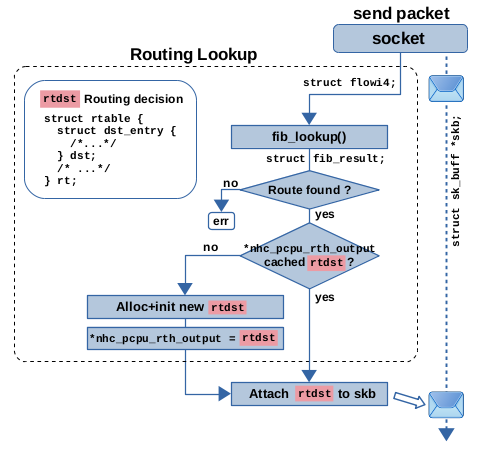
图 7:本地输出路径上的路由表查找和下一跳缓存
FIB Nexthop Exception Caching
这种机制实际上与上述描述的下一跳缓存非常相似。在现代内核中,它实际上与该机制共存;然而,它仅在下一跳异常情况下使用。什么是下一跳异常?嗯,路由条目可以被用户修改,也可以被诸如 ICMPv4 重定向消息或路径 MTU 发现之类的机制修改。
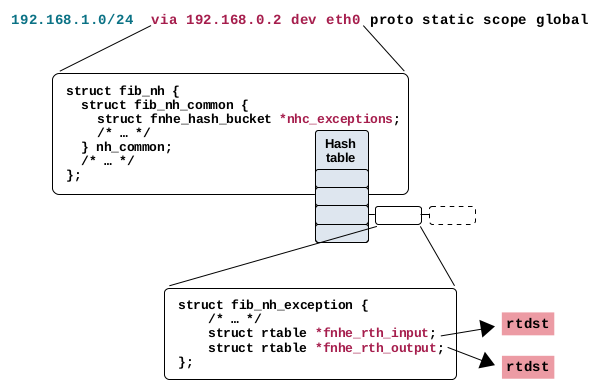 图8:下一跳异常存储在下一跳实例的哈希表成员中。它们具有用于缓存接收路径和本地输出路径上的路由决策的成员变量
图8:下一跳异常存储在下一跳实例的哈希表成员中。它们具有用于缓存接收路径和本地输出路径上的路由决策的成员变量
这样的更改不会覆盖现有的路由条目。如图8所示,struct fib_nh_common 包含一个名为 *nhc_exceptions 的成员,其中在这些情况下包含一个哈希查找表,用于存储对该路由条目的异常情况。这些异常情况由 struct fib_nh_exception 的实例表示。该结构的成员 *fnhe_rth_input 和 *fnhe_rth_output 被用来以与用于下一跳缓存的 struct fib_nh_common 成员相同的方式缓存路由决策。
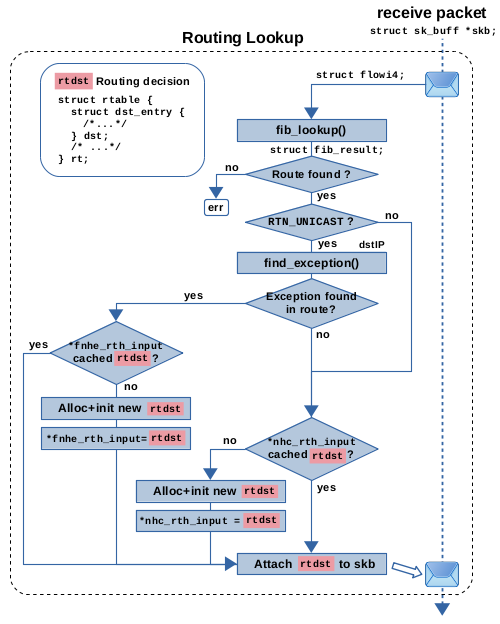
图 9:路由表查找 + FIB 下一跳异常缓存 (fnhe) + 接收路径上的下一跳缓存
图9说明了这在接收路径上的工作原理。请将其与图6进行比较。图9展示了相同的下一跳缓存,但添加了下一跳异常缓存机制作为额外的细节。后一种机制实际上只对接收路径上的数据包执行,这些数据包将被转发,而不是发往本地接收(检查 RTN_UNICAST)。如果 fib_lookup() 的结果确定要转发数据包,则调用 find_exception() 函数以检查匹配的路由条目是否包含与数据包目标 IP 地址匹配的异常。如果不是这种情况,则一切都按照前一节中描述的方式工作。如果找到匹配的异常,将检查成员 *fnhe_rth_input 是否存在缓存的路由决策,如果存在,则使用该路由决策并将其附加到数据包上。否则,将分配并初始化一个新的路由决策对象,将其缓存在 *fnhe_rth_input 中,并附加到数据包上。因此,缓存机制的工作方式类似于下一跳缓存。
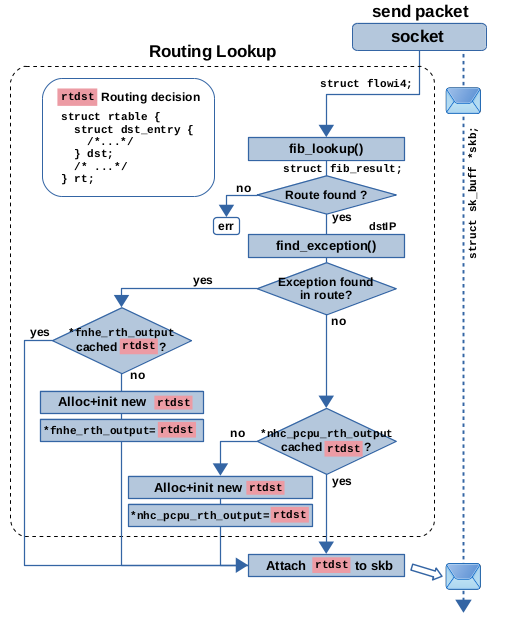 图 10:本地输出路径上的路由表查找 + FIB 下一跳异常缓存 (fnhe) + 下一跳缓存
图 10:本地输出路径上的路由表查找 + FIB 下一跳异常缓存 (fnhe) + 下一跳缓存
图10说明了这在本地输出路径上的工作原理。请将其与图7进行比较。图10展示了相同的下一跳缓存,但添加了下一跳异常缓存机制作为额外的细节。调用 find_exception() 函数来检查由 fib_lookup() 返回的匹配路由条目是否包含与数据包目标 IP 地址匹配的下一跳异常。如果不是这种情况,则一切都按照前一节中描述的方式工作。如果找到匹配的异常,则检查成员 *fnhe_rth_output 是否存在缓存的路由决策,如果存在,则使用该决策。否则,将分配并初始化一个新的路由决策对象,并在 *fnhe_rth_output 中进行缓存。将路由决策实际附加到数据包发生在调用堆栈上几层的函数中的稍后时间点。
Socked Caching (TX)
这个缓存特性被用于本地输出路径;因此,仅用于发送本地生成的数据包,而不是接收或转发的数据包。当系统上的套接字(例如 TCP 或 UDP 套接字,客户端或服务器)在网络上发送数据时,只需要对它发送的第一个数据包进行一次路由查找即可。毕竟,对于它发送的所有后续数据包,目标 IP 地址都是相同的,路由决策也是相同的。因此,一旦从初始查找中获取了路由决策对象,它就会被缓存在套接字内。这个特性已经存在很长时间了。它已经存在于 3.6 之前的内核版本中,并与旧的路由缓存共存。它仍然存在于现代内核中,并与描述的下一跳缓存和下一跳异常缓存共存。实际上,它是建立在这些缓存特性之上的,如图11所示。换句话说,对于由本地套接字生成并要发送到网络的每个数据包,首先检查套接字缓存。如果它已经包含一个路由决策对象,那么就将其附加到数据包上,一切都完成了。否则,执行完整的路由查找。在 3.6 之前的内核中,这意味着路由缓存查找,加上(如果需要)基于策略的路由和路由表查找。在现代内核中,这意味着基于策略的路由、路由表查找,然后是下一跳缓存或下一跳异常缓存。由于这个特性,我在上面的章节中强调了,在本地输出路径上,路由决策对象并不立即被附加到数据包上。这个逻辑与套接字缓存集成在一起,最终,一个对象被附加到数据包上,它可以来自套接字缓存,也可以来自路由表查找,也可以来自下一跳缓存或下一跳异常缓存。
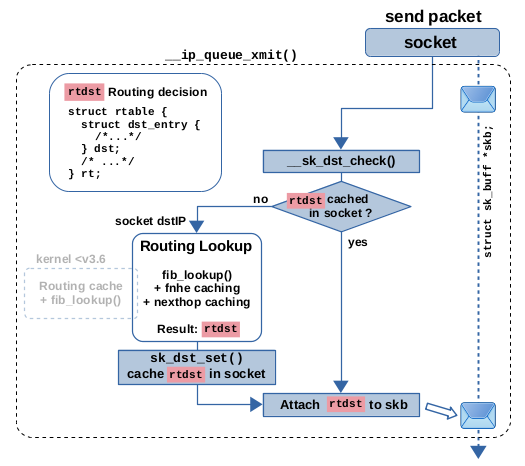 图 11:本地输出路径上的路由表查找和基于套接字的缓存
图 11:本地输出路径上的路由表查找和基于套接字的缓存
对于 TCP,您可以在 v3.6 之前的内核的函数 ip_queue_xmit() 和 v5.14 内核的函数 __ip_queue_xmit() 中找到此功能。这两个版本之间的代码基本相同。函数 __sk_dst_check() 用于检查套接字缓存中的路由决策对象,它又调用了 __sk_dst_get()。缓存本身是作为套接字结构的成员 sk_dst_cache 实现的。
struct sock {
/* ... */
struct dst_entry __rcu *sk_dst_cache;
};
如果该缓存当前不持有路由决策对象,则会调用 ip_route_output_ports(),该函数执行了如上所述的完整路由查找过程。然后,在函数 sk_setup_caps() 中将得到的路由决策对象存储在套接字缓存中,该函数又调用了函数 sk_dst_set()。最后,无论是否存在缓存,路由决策都会通过函数 skb_dst_set_noref() 附加到网络数据包上。
Socket Caching (RX)
还有另一个基于套接字的缓存特性。然而,这个特性只存在于现代内核中。它也被称为 IP 提前解复用,针对的是接收路径上的网络数据包,这些数据包最终会被系统上的本地 TCP/UDP 套接字接收到;请参见图12。
 图 12:在接收路径上进行路由查找之前,TCP/UDP 套接字的 IP 早期解复用
图 12:在接收路径上进行路由查找之前,TCP/UDP 套接字的 IP 早期解复用
没有这个特性,普通的路由查找,包括下一跳缓存,将确定数据包是否要传递到本地。这个特性在函数 ip_rcv_finish_core() 中的接收路径上的路由查找之前直接增加了一个额外的哈希表查找。这个哈希表包含了当前系统上已经建立连接的 TCP/UDP 套接字。根据网络数据包的源 IP 地址、目标 IP 地址、TCP/UDP 源端口和目标端口、输入接口以及网络命名空间进行哈希查找。如果找到匹配项,则返回指向表示匹配套接字的 struct sock 实例的指针。在上一节中,您看到这个结构有一个成员变量 sk_dst_cache,用于在输出路径上缓存路由决策对象。对于这个提前解复用(early demux)特性,该结构提供了另一个成员来缓存路由决策,名为 sk_rx_dst。
struct sock {
/* ... */
struct dst_entry *sk_rx_dst;
};
如果该成员已经保存了一个路由决策,那么在进行一些有效性检查后,它将被附加到网络数据包上。因此,可以跳过正常的路由查找,数据包通过 dst_input() 间接调用附加的路由决策对象在其 (*input)() 函数指针中保存的内容,继续在本地输入路径上移动,这意味着, ip_local_deliver() 正在被调用。与旧的路由缓存相比,这个特性不会以相同的方式受到 DoS 攻击的影响,因为仅仅向系统发送一个包含新的源和目标 IP 地址对的 IP 数据包是不足以在哈希表中创建另一个条目的。只有在系统上的现有套接字达到已建立状态时才会添加新条目,并且这是在 OSI 第4层处理中完成的,例如,对于 TCP 是在函数 tcp_rcv_established() 中。sysctl在网络命名空间级别实现的,以便在网络命名空间内全局开启/关闭此功能,或者仅对 TCP 和/或 UDP 开启/关闭(默认情况下为开启)。
$ sudo sysctl -a -r early_demux
net.ipv4.ip_early_demux = 1
net.ipv4.tcp_early_demux = 1
net.ipv4.udp_early_demux = 1
Hint caching
这是否实际上是一个缓存特性是值得商榷的。然而,它是基于路由决策对象的又一个运行时优化,使得在某些情况下可以跳过接收路径上的实际完整路由查找。您只会在现代内核中找到它。正如我在之前的文章中提到的,接收路径上的 IPv4 数据包可以通过函数 ip_rcv() 逐个处理,也可以根据数据包列表由函数 ip_list_rcv() 处理。这个优化特性仅在后一种情况下使用。为了解释它,让我首先解释一下当涉及到接收路径上的路由查找时,基于列表的数据包处理是如何工作的。图 13 对此进行了说明。
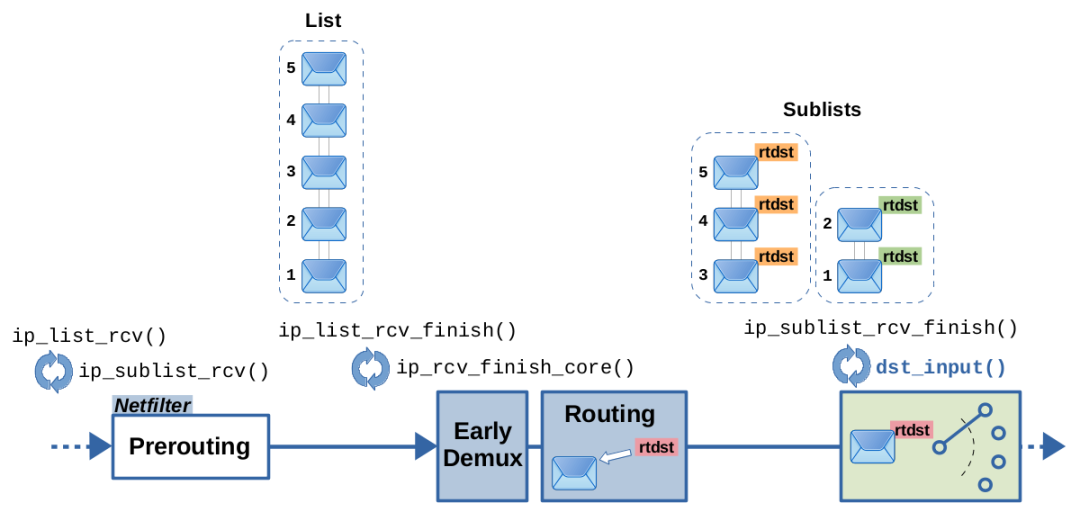 图 13:接收路径上基于列表的数据包处理
图 13:接收路径上基于列表的数据包处理
在 Netfilter Prerouting hook遍历后,会调用函数 ip_list_rcv_finish() 并给定一个数据包列表。该函数循环遍历列表中的数据包,并为每个数据包调用 ip_rcv_finish_core()。后者包含了提前解复用(early demux)特性和完整的路由查找,包括上面解释过的下一跳异常和下一跳缓存特性。在循环遍历数据包时,ip_list_rcv_finish()基于附加的路由决策,将它们分组成子列表;也就是说,获得相同路由决策的连续数据包会进入同一个子列表。通常情况下,接收到的连续数据包很可能具有相同的源和目标,因此附加的路由决策也相同。因此,这种分组是有意义的。然后,这些子列表依次输入函数 ip_sublist_rcv_finish(),它会遍历给定子列表的数据包,并为每个数据包调用 dst_input()。到目前为止一切都很好。现在让我们来看一下这个优化特性;请参见图 14。
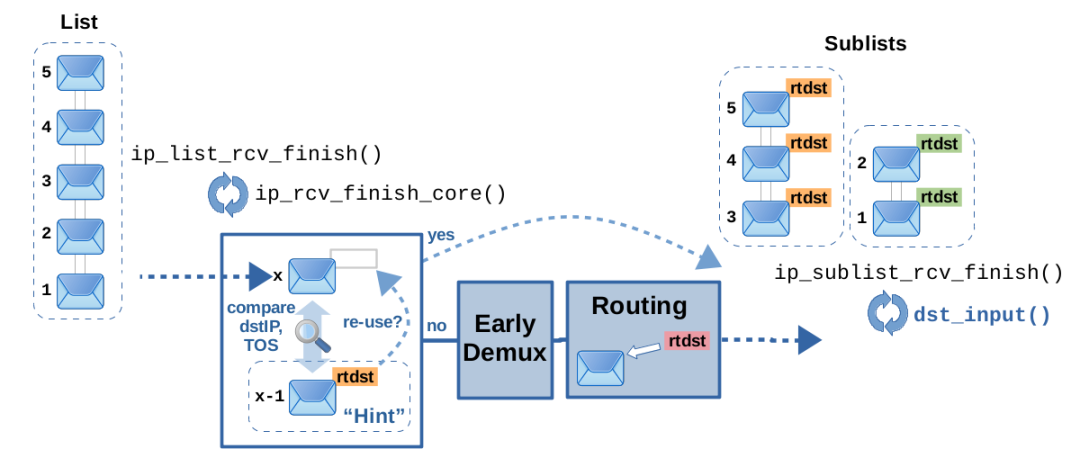 图14:利用先前的数据包作为提示,并检查是否可以重用其附加的路由决策
图14:利用先前的数据包作为提示,并检查是否可以重用其附加的路由决策
在 ip_list_rcv_finish() 循环遍历其给定列表的数据包时,它会将先前处理的数据包记为下一个数据包的提示。正如我所说的,同一列表中的连续数据包很可能会附加相同的路由决策。因此,当为下一个数据包调用 ip_rcv_finish_core() 时,它会以前一个数据包作为提示,并比较两个数据包的目标 IP 地址和 TOS 值。如果它们相同,那么就可以简单地重用先前数据包附加的路由决策用于下一个数据包。因此,在这种情况下可以跳过提前解复用和实际路由查找,从而提高运行时速度。然而,这个特性也有一些限制。ip_list_rcv_finish() 中的 ip_extract_route_hint() 函数会检查广播数据包是否可用,并在存在非默认的基于策略的路由规则时进行检查。请记住,虽然默认规则不受此影响,但是“真正”的基于策略的路由规则实际上可以根据诸如数据包的源 IP 地址、skb->mark 等参数选择不同的路由表进行查找。因此,在这种情况下,仅仅因为具有相同的目标 IP 地址和 TOS 值而简单地重用先前数据包的路由决策是不可行的。
Flowtables
Flowtables 是由 Netfilter 开发人员实现的软件(在某些情况下也可以是硬件)快速路径机制,它通过使转发的网络数据包跳过正常的慢路径处理的大部分内容来加速。它由 Nftables 设置规则,基于连接跟踪功能,并在哈希表中缓存路由决策。在接收Netfilter Ingress hook的早期,对该表进行查找,从而对网络数据包进行快路径/慢路径解复用。
Cache Invalidation
如果发生某些更改,例如向路由表添加新条目或网络接口的up/down状态更改。这些事件以及许多其他事件都会使当前缓存的路由决策变得过时。因此,必须有一种方法来摆脱它们。这被称为缓存失效(cache invalidation),而且似乎已经在很长一段时间内以相同的方式实现,可以追溯到早于 v3.6 的内核版本。换句话说,无论我们是否在讨论旧的路由缓存还是我在上面章节中描述的任何较新的缓存机制,它们都使用相同的方式来使已过时的缓存路由决策对象失效。那么,这是如何工作的呢?在使缓存失效的事件发生时,您基本上需要清理系统中当前缓存的所有决策,并且需要立即执行此操作,甚至需要阻止使用缓存直到清理完成。这会突然消耗大量的 CPU 和 RAM。后者是因为您无法立即删除当前仍在使用中(仍附加到 skbs 上)的决策,而需要将这些放入垃圾列表中。似乎很久以前就是这样做的。但是,开发人员提出了一种更加优雅的方式,可以追溯到这个提交。他们为每个路由决策实例添加了一个所谓的“生成标识符”,并创建了一个全局对应项,因此只需更改此全局生成标识符即可执行缓存失效,而无需扫描所有实例。这个“全局”生成标识符以原子整数 rt_genid 的形式在每个网络命名空间中全局实现:
struct net {
/* ... */
struct netns_ipv4 {
/* ... */
atomic_t rt_genid;
} ipv4;
};
使缓存失效的事件需要调用函数 rt_genid_bump_ipv4(),该函数原子地增加这个整数。此外,每个缓存条目(即每个路由决策对象)都需要一个自己的生成标识符成员 rt_genid,作为全局生成标识符的对应项:
struct rtable {
struct dst_entry {
short obsolete;
/* ... */
} dst;
int rt_genid;
/* ... */
};
当通过 rt_dst_alloc() 或 rt_dst_clone() 分配新的路由决策对象时,其生成标识符被简单地设置为全局生成标识符的当前值。整数 obsolete 在这里也起作用。这两个函数都将其设置为 DST_OBSOLETE_FORCE_CHK。此值指定必须使用生成标识符机制来处理该实例。因此,当路由决策即将再次使用时(例如,当它即将附加到另一个 skb 时),其生成标识符值需要与全局值进行比较,这由函数 rt_is_expired() 完成。如果两者不相等,则缓存条目被视为过期。例如,在上面描述的下一跳缓存机制中,该函数被封装在函数 rt_cache_valid() 内,该函数首先检查成员 obsolete 的值:
static bool rt_cache_valid(const struct rtable *rt)
{
return rt &&
rt->dst.obsolete == DST_OBSOLETE_FORCE_CHK &&
!rt_is_expired(rt);
}
你可以看到,如果 obsolete 包含另一个值,那么 rt_is_expired() 就不会被调用,但这个实例仍然会被视为过期。还有许多其他函数最终都会调用 rt_is_expired()。图 15 显示了其中的一些函数;不能保证完整性。你可能会认出这些调用源自上面描述的几种缓存和优化功能,比如基于套接字的缓存、早期解复用和流表。
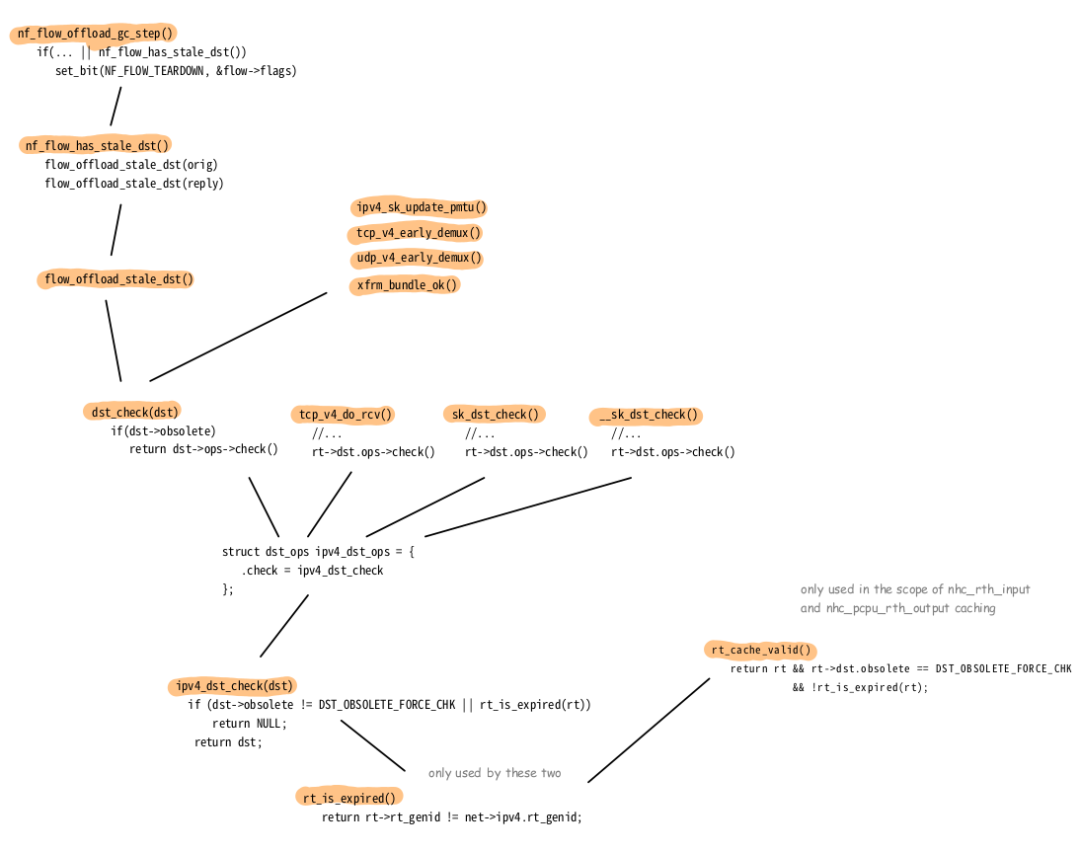 图 15:调用 rt_is_expired() 的函数概述
图 15:调用 rt_is_expired() 的函数概述
有许多事件会调用 rt_genid_bump_ipv4(),从而使所有当前缓存的路由决策失效。图 16 显示了其中的一些事件;不能保证完整性。示例包括路由表中的内容更改、MAC 地址更改、网络设备配置和状态(up/down)更改、对与网络堆栈相关的 sysctl 的写入、IPsec(xfrm)策略更改等。
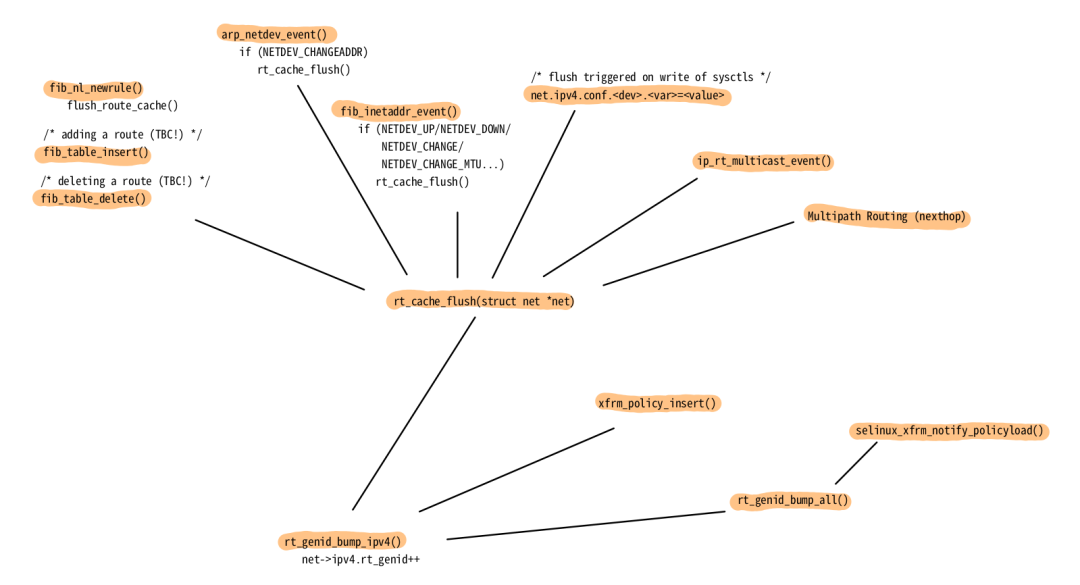 图 16:导致 rt_genid 增加的事件概览
图 16:导致 rt_genid 增加的事件概览
The Slab Cache
这实际上并不是一个路由缓存机制。我在这里提到它只是为了避免混淆。Slab 缓存或 Slab 分配是 Linux 内核中常见的内存分配机制。它用于需要非常频繁地分配和释放相同类型和大小的对象的情况,比如文件描述符、调度程序处理的任务、skbs 等等。简单地说,这种分配机制为某种数据类型和大小的多个实例提供了预分配的缓存。因此,该类型的实例的分配可以非常快速地完成。释放通常不会实际释放已分配的内存。它只是释放缓存中的一个插槽,该插槽将被保留以供即将发生的另一个分配重用。路由决策,即struct rtable 及其内部的 struct dst_entry 实例,都是通过这种 Slab 分配机制进行分配和释放的。这适用于这些结构的所有实例,无论它们最终是否被用于我上面描述的任何一个路由缓存机制中,还是它们只是附加到单个 skb。您可以在函数 rt_dst_alloc() 中观察到这一点,该函数分配和初始化一个新的路由决策。它调用 dst_alloc(),后者又调用 kmem_cache_alloc() 来进行实际的内存分配。后者是 Slab 分配器提供的接口的一部分。用于释放的对应函数是 kmem_cache_free(),它由 dst_destroy() 调用。struct rtable 实例的 Slab 缓存是在函数 ip_rt_init() 中通过调用 kmem_cache_create() 进行初始化的。如果您想进一步阅读:博客文章The Slab Allocator in the Linux kernel (Andria Di Dio, 2020)非常好地描述了 Slab 分配的概念及其在 Linux 上的实现。关于如何防止/添加更多混淆的另一个细节:Slab 分配机制的编程接口有 3 种不同的后端:SLOB、SLAB 和 SLUB。在现代内核中,默认使用 Slub。您可以在构建内核时在这三种后端中选择。
Context
在 Debian 11 (bullseye) 系统上观察到所描述的行为和实现,该系统在 amd64 架构上使用 Debian 向后移植,使用内核版本 5.14.7。一个例外是“旧”路由缓存部分,它描述了内核版本 3.5。
Ref
https://thermalcircle.de/doku.php?id=blog:linux:routing_decisions_in_the_linux_kernel_2_caching
推荐本站淘宝优惠价购买喜欢的宝贝:

本文链接:https://www.hqyman.cn/post/11932.html 非本站原创文章欢迎转载,原创文章需保留本站地址!

 微信支付宝扫一扫,打赏作者吧~
微信支付宝扫一扫,打赏作者吧~休息一下~~