
Log Parser Lizard 8.7:一款用于高级日志分析的动态图形界面工具,使用 SQL 查询多种结构化日志数据,包括服务器日志和 Windows 事件日志。体验直观的图形用户界面(GUI),配备语法编辑器、数据网格、图表工具等。借助正则表达式(regex)、GROK 和自定义插件,提升解析能力。
Log Parser Lizard: Advanced SQL Analysis for Log Files
Log Parser Lizard version 8.7
lizardlabs (Lizard Labs Software) · GitHub
Log Parser Lizard:一款用于高级日志分析的动态图形界面工具
使用 SQL 查询多种结构化日志数据,包括服务器日志和 Windows 事件日志。
体验直观的图形用户界面(GUI),配备语法编辑器、数据网格、图表工具等。
借助正则表达式(regex)、GROK 和自定义插件,提升解析能力。
高效查询远程数据库(如 MS SQL Server 和 SQLite),支持 SQL 和内联 .Net 代码的集成。
下载
简化您的日志数据分析流程:Log Parser Lizard
解锁高效的日志解析和数据查询功能,通过 Log Parser Lizard 快速从日志中提取关键见解。我们的软件通过 Microsoft Log Parser 2.2 提供了一个用户友好的图形界面(GUI),支持多种 Windows 版本。
Log Parser Lizard 非常适合开发人员、系统管理员、审计员和信息安全团队,它能够对多种结构化日志数据类型执行 SQL 查询。这些数据类型包括:Web 服务器日志、Windows 系统事件以及应用程序日志文件(如 log4j、log4net、nlog、serilog),还支持 CSV、TSV、JSON 和 XML 格式。该软件还支持对远程服务器数据库的查询,兼容 Microsoft SQL Server、SQLite、MySQL、OLE DB 等数据库。使用 Log Parser Lizard,可以简化日志数据分析、威胁检测、数据收集、导出、可视化、商业智能(BI)、报告和 ETL 等任务,并提高效率。
通过 SQL 查询高效分析日志文件,告别数据库存储:
SELECT DISTINCT src-ip FROM firewall.log WHERE action='DROP'
SELECT TOP 100 * FROM c:\webserver.log WHERE sc-status <> 200
SELECT cs-uri-stem FROM c:\InetPub\Logs\ex*.logGROUP BY cs-uri-stem HAVING COUNT(*) > 50
SELECT to_lowercase(extract_extension(cs-uri-stem)) AS PageType, SUM(sc-bytes)FROM ex131118.log, ex131119.log GROUP BY PageType
通过 Log Parser Lizard 直观的 GUI 提升日志数据的导航和理解,使分析过程变得更加简便高效。
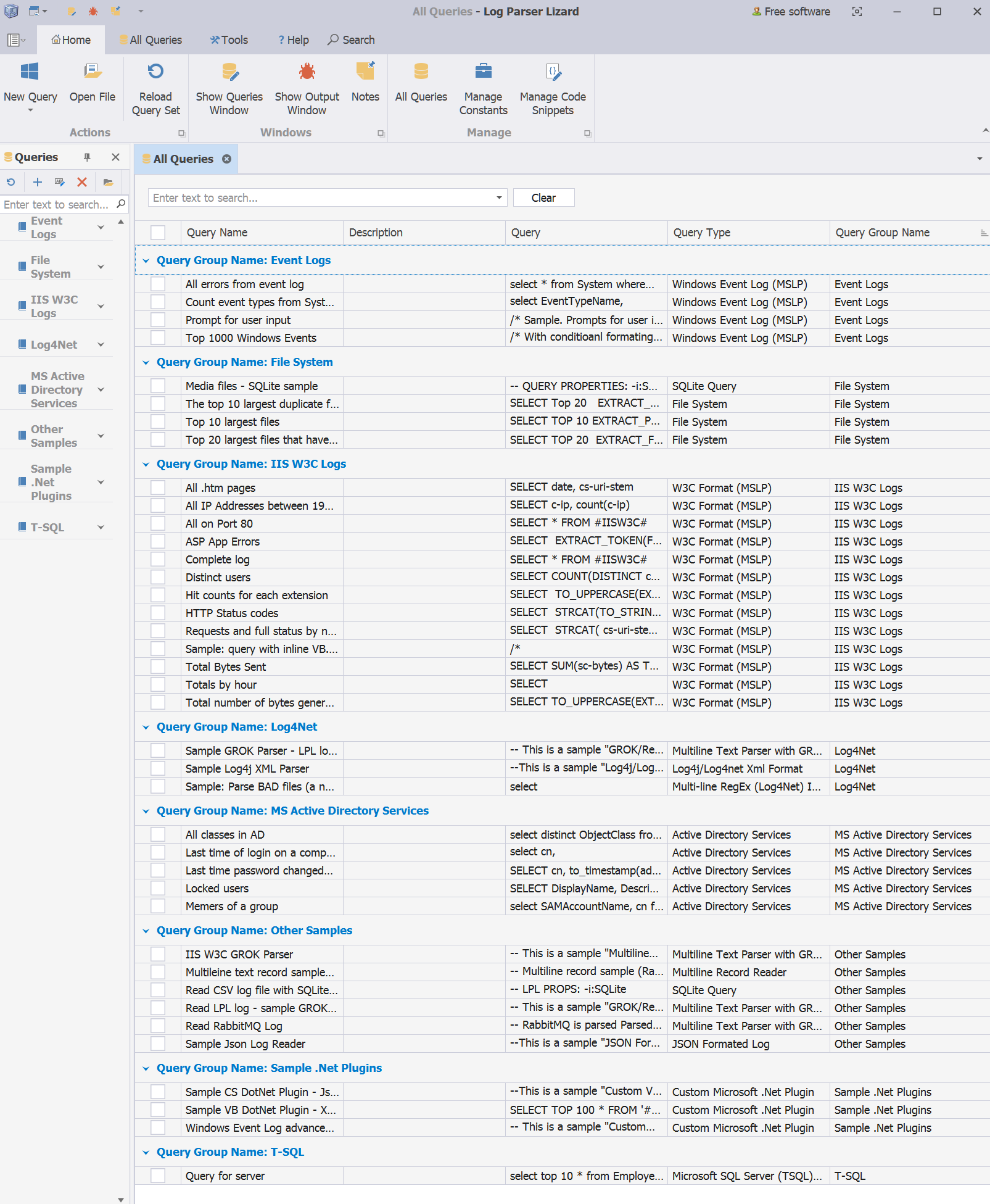
Log Parser Lizard:每个文件都能成为可查询的数据库
MS Logparser 和 Log Parser Lizard 对系统管理员和开发人员来说至关重要,它们优化了法医分析、调试、日志收集、大数据分析、数据可视化和报告等任务。在数据管理流程中,它们的集成对于提升效率和洞察力至关重要。
全球数千名用户信赖其稳定性和功能。
在 VirusTotal 上通过安全认证,确保软件的安全性。
提供比领先的高级产品更强大的功能,同时仍然经济实惠。
通过 Log Parser Lizard 改变您的日志数据分析方式,立即下载,提升您的数据驱动策略,解锁新的生产力水平,助力您的日志与数据分析任务。
关于 Log Parser Lizard 用户最喜爱的功能的中文总结表格:
| 功能 | 描述 |
|---|---|
| SQL日志查询 | 使用熟悉的SQL语法轻松查询大量日志数据。支持复杂的SQL查询,包括函数、连接、联合等操作。 |
| 用户界面 | 现代化的Office风格界面,带有功能区和标签,专为专业人士设计,优化了日志文件分析的用户体验。 |
| 高级查询编辑器 | 查询编辑器提供语法高亮、自动补全、代码片段、查询常量以及内联VB.NET代码等功能,使查询创建更加高效。 |
| 查询管理 | 高效组织和管理您的Log Parser Lizard查询,提供全面的查询管理功能。 |
| 数据导航和可视化 | 高级输出表格功能,如排序、分组、搜索、过滤、条件格式化、公式字段、列选择和图表创建等。 |
| 高级数据过滤 | 使用类似Excel的UI元素创建高级过滤表达式,包括查询生成器、即时查找和自动过滤行等。 |
| 处理大日志文件 | 无文件大小限制。根据硬件性能,快速处理极大的日志文件。 |
| 支持自定义日志格式 | 使用正则表达式和Grok解析非结构化数据为结构化格式,支持.gz日志、加密日志及log4net/log4j XML格式。 |
| 数据透视表和树形图 | 提供先进的数据透视表和树形图功能,进行多维数据分析和数据挖掘,提供可操作的洞察力。 |
| 直观的仪表板 | 通过拖放UI元素,如图表、数据透视表、数据卡、仪表、地图或网格,轻松构建仪表板,轻松处理数据绑定和过滤。 |
| 所见即所得报告设计器 | 简单直观的报告设计器,将文字处理器的易用性与带状报告设计器的强大功能相结合。 |
| Web API服务器 | 内置Web服务器支持JSON输出的查询执行,允许与外部数据分析软件集成,并通过Web浏览器远程访问查询。 |
| 打印和数据导出 | 提供强大的导出和打印选项,支持多种格式,如XLS、XLSX、PDF、RTF、TXT、MHT、CSV、HTML和图像格式等。 |
| 性能优化 | 专为快速响应和高效性能设计,能够轻松处理复杂的大数据集。 |
| 探索更多功能 | 通过下载Log Parser Lizard,发现更多功能、帮助文件和示例。 |
这些功能使Log Parser Lizard成为一个强大且高效的日志分析、数据可视化和报告工具,确保用户能够轻松管理和分析大量的日志数据。
Log Parser Lizard 支持的所有输入格式的中文表格化总结:
| 输入格式 | 描述 |
|---|---|
| W3C 输入格式 | 解析 W3C 扩展日志文件格式:Microsoft IIS、FTP、Apache、Exchange 跟踪、SharePoint、个人防火墙、Microsoft ISA 服务器、Windows Media 服务、SMTP 等。 |
| Windows 事件日志 | 读取本地和远程系统、应用程序、安全以及自定义事件日志的信息,包括事件日志备份文件 (.evtx)。 |
| Active Directory 服务 | 使用 SQL 枚举 Active Directory 对象。 |
| 逗号分隔值(CSV) | 许多应用程序和工具(如 Microsoft Excel 和 PerfMon)生成的 CSV 文本文件。 |
| 制表符分隔值(TSV) | 许多命令行工具输出的格式。 |
| 正则表达式增强 | 适用于解析基于文本的日志文件,支持正则表达式和 GROK 别名,几乎任何文本文件都可以视为数据库。 |
| Log4j 和 Log4net XML 格式 | 解析 Apache log4j/log4net XML 文件格式。 |
| JSON 格式日志 | 读取 JSON 格式的日志文件。 |
| GROK/正则表达式文本解析器 | 使用 GROK 语法解析非结构化日志数据为结构化格式,简单高效,适用于文本文件的快速解析。 |
| XML 输入格式 | 解析多种 XML 文档和配置文件,可以以不同方式处理。 |
| 文本行输入格式 | 解析任何不被原生支持的文本文件格式,比 grep 更强大。 |
| IIS W3C 日志 | 解析 Microsoft IIS 网站日志(W3C 扩展格式)。 |
| 文件系统 | 使用 SQL 枚举文件和目录信息。 |
| 媒体文件 | 使用 SQL 枚举视频、图片、音频文件并获取元数据。 |
| 注册表值 | 枚举本地或远程注册表键和值。 |
| Logparser COM 输入插件 | 使用自定义插件查询任何数据源。 |
| IIS 日志文件格式 | 解析 IIS 日志文件格式。 |
| IIS 集中式二进制日志文件 | 解析 IIS 集中式二进制日志格式。 |
| Windows 企业跟踪(ETW) | 解析 Windows 企业跟踪日志。 |
| 多行正则表达式(Log4Net 或 NLOG) | 解析 Log4Net 或 NLOG 多行日志。 |
| SQL Server T-SQL 查询 | 使用 LPL 查询关系型数据库。 |
| C#(C-Sharp).Net 数据源 | 运行简单的 C# 代码并将数据以表格形式显示。 |
| HTTP 错误日志 | 解析 HTTP 错误日志。 |
| IIS ODBC | 使用 ODBC 连接解析 IIS 日志数据。 |
| NCSA 日志文件格式 | 解析 NCSA 日志文件格式。 |
| NetMon 网络监视器 | 解析 NetMon 网络监视器日志。 |
| TEXTWORD 输入格式 | 解析包含 Word 文本数据的日志文件。 |
| URLScan IIS 过滤器 | 解析 URLScan IIS 过滤器日志。 |
| 正则表达式输入格式 | 使用正则表达式格式解析日志数据。 |
| OLE DB SQL 查询(MySQL, Oracle 等) | 支持 MySQL、Oracle、Access、PostgreSQL 等数据库的 OLE DB SQL 查询。 |
| 文本文件正则表达式输入格式 | 解析文本文件并使用正则表达式进行查询。 |
| Google BigQuery | 支持 Google BigQuery 查询。 |
| 终极日期表 | 处理日期相关的数据表。 |
| 终极数字表 | 处理数字相关的数据表。 |
| HTML 表格读取器 | 读取 HTML 格式的表格数据。 |
| Excel 文件读取器 | 读取 Excel 文件格式的数据。 |
| Visual Basic .Net 数据源 | 使用 Visual Basic .Net 作为数据源执行查询。 |
| PowerShell 脚本 | 使用 PowerShell 脚本获取数据并进行查询。 |
| Microsoft SQL Server Compact Edition (CE) | 支持 Microsoft SQL Server Compact Edition 数据源。 |
| SQLite | 支持 SQLite 数据源。 |
这些输入格式让 Log Parser Lizard 能够灵活地处理来自不同来源的数据,支持各种日志、文件格式以及数据库查询,极大地扩展了其分析能力。
Log Parser Lizard 是什么?
Log Parser Lizard 是一款强大的日志分析工具,基于 SQL 查询语言设计,专门用于解析、处理和分析各种类型的日志文件。它提供了一个直观的用户界面,使用户能够轻松地加载、查询和转换日志数据,适用于系统管理员、开发人员、数据分析师等角色。
主要特点:
支持多种日志格式:Log Parser Lizard 可以处理常见的日志格式,如 Apache 和 IIS Web 服务器日志、Windows 事件日志、CSV、XML、JSON 等。
SQL 查询支持:用户可以通过 SQL 查询语言进行数据筛选、聚合和统计分析,极大简化了日志分析工作。
数据可视化功能:支持生成图表和图形,如柱状图、折线图、饼图等,方便对数据进行可视化展示。
灵活的输出格式:支持将分析结果导出为 CSV、Excel、HTML 等格式,便于后续处理和报告生成。
可扩展性:用户可以将分析过程自动化,进行定期任务设置,并与其他工具结合进行进一步分析。
Log Parser Lizard 怎么样?
Log Parser Lizard 的表现是相当出色的,特别是在处理大量日志数据时,提供了非常高效且易于使用的功能。以下是一些它的关键优点:
1. 用户友好界面:
Log Parser Lizard 提供了一个图形化用户界面(GUI),大大简化了传统命令行工具的使用,适合没有深厚 SQL 基础的用户。
对于熟悉 SQL 的用户,提供了类似数据库管理工具的直观操作体验,可以像操作数据库一样对日志进行查询和分析。
2. 高效的数据处理能力:
它能够轻松地处理和分析海量日志数据,适用于大规模的日志文件分析。
内置的查询优化引擎支持快速执行复杂的查询,甚至在资源有限的情况下也能较好地完成任务。
3. 多样化的输出选项:
分析结果可以导出为多种格式(如 CSV、Excel),方便进一步处理或生成报告。
生成的报告和图表可以直接用于决策支持或分享给团队成员。
4. 高度的灵活性与扩展性:
支持对日志文件进行定制化查询,可以灵活选择字段、设置过滤条件以及进行聚合统计。
支持脚本化操作,可以将常用的查询和任务进行自动化处理,适合定期的日志分析任务。
Log Parser Lizard 为什么有用?
Log Parser Lizard 的价值在于它能帮助用户高效地从庞大且杂乱无章的日志数据中提取出有价值的信息。以下是它的一些应用场景和价值所在:
1. 提升日志分析效率:
对于需要分析大量 Web 服务器、应用程序日志或系统日志的用户来说,Log Parser Lizard 提供了非常高效的解决方案。通过 SQL 查询,可以直接对日志文件进行复杂的筛选、排序、统计分析,大大节省了人工分析的时间。
2. 多格式支持,灵活性高:
无论是 Web 服务器日志、数据库日志,还是操作系统事件日志,Log Parser Lizard 都能轻松解析。用户可以根据自己的需求选择适合的日志源,进行统一的查询和分析。
3. 强大的数据可视化与报告功能:
分析结果可以通过图表和图形形式呈现,使得数据更加直观易懂。对于管理层或非技术团队的成员来说,这种图形化的呈现方式能够有效地帮助他们理解数据背后的趋势和问题。
4. 便于监控与问题诊断:
Log Parser Lizard 可以帮助系统管理员快速识别日志中的异常模式、错误或性能瓶颈。例如,快速找出服务器错误、资源使用过高的原因,甚至检测到潜在的安全威胁(如频繁的 404 错误或异常的请求模式)。
5. 适合自动化任务与批量处理:
日志分析通常需要定期进行,Log Parser Lizard 支持自动化任务的设置。例如,通过脚本和任务调度器定时执行日志分析任务,自动生成报告并发送到指定邮箱,这对于需要定期监控和报告的场景非常有帮助。
为什么选择 Log Parser Lizard?
高效与易用:凭借其 SQL 查询的强大功能和用户友好的界面,Log Parser Lizard 为日志分析提供了高效且简单的解决方案,尤其适合没有深入编程经验的用户。
适应性强:它支持多种日志格式,并且能够灵活扩展,适用于各种不同的分析需求。
自动化与可视化功能:它能够帮助用户自动化日志分析过程,并生成易于理解的可视化报表,方便决策和进一步分析。
Log Parser Lizard 是一个集成日志分析、自动化报告和数据可视化的强大工具,适用于从个人开发者到大型企业的各种日志分析需求。
Log Parser Lizard 的功能分类表格,帮助更直观地理解其各项功能:
| 功能类别 | 功能描述 | 示例/备注 |
|---|---|---|
| 日志解析与导入 | 支持多种日志格式解析与导入 | 支持 Apache、IIS、Windows 事件日志、CSV、XML、JSON 等格式 |
| SQL 查询 | 通过 SQL 查询语句对日志进行筛选、排序、聚合、统计等操作 | 类似于数据库查询,支持 SELECT、WHERE、GROUP BY 等 SQL 操作 |
| 数据过滤 | 对日志数据进行过滤,提取符合条件的记录 | 例如提取特定时间段内的访问日志,或提取特定错误类型的日志 |
| 数据聚合 | 支持对日志数据进行聚合统计,如计算总数、平均值、最大值、最小值等 | 如按小时统计访问量、计算错误率等 |
| 时间解析 | 支持多种时间格式,能够对时间字段进行转换、比较和筛选 | 支持日期、时间、时间戳等多种格式 |
| 日志输出与导出 | 支持将分析结果导出为多种格式,包括 CSV、Excel、HTML、XML 等 | 方便将数据导出到其他工具或生成报告 |
| 数据可视化 | 提供图表和图形展示,支持柱状图、折线图、饼图等多种可视化形式 | 可生成趋势图、分布图等,帮助用户理解数据 |
| 脚本与自动化 | 支持创建自动化任务,定期执行日志分析并生成报告 | 可通过任务调度器设置定时任务,定期分析日志并自动发送报告 |
| 多任务处理 | 支持同时处理多个日志文件或多个查询任务 | 可同时加载多个文件并进行并行分析 |
| 错误与异常检测 | 支持对日志中的错误或异常模式进行识别和高亮显示 | 可识别频繁出现的 404 错误或资源请求异常等 |
| 数据库兼容性 | 支持与数据库结合使用,能够通过 SQL 查询将日志数据与数据库数据进行比较 | 可与 MySQL、SQL Server、Oracle 等数据库结合 |
| 实时日志监控 | 支持实时监控和分析正在生成的日志文件 | 对实时日志流进行分析,及时发现潜在问题 |
| 支持正则表达式 | 支持使用正则表达式对日志数据进行高级过滤和匹配 | 可以更灵活地提取特定格式的数据 |
| 图形界面 | 提供直观的图形用户界面,方便用户无需编程即可进行日志分析 | 类似数据库管理工具的界面,支持拖拽式查询操作 |
| 定制查询 | 支持对日志字段和查询进行高度定制,适应不同分析需求 | 用户可以自由定义查询条件,定制化分析数据 |
| 跨平台支持 | 支持在 Windows 系统上运行,能够处理本地和远程日志文件 | 可以分析本地文件,也可以通过网络分析远程日志 |
这个表格总结了 Log Parser Lizard 各类功能及其应用场景,帮助用户更好地理解工具的强大功能和灵活性。
Log Parser Lizard 是一款强大的日志分析工具,其底层原理基于 SQL 查询语言和日志解析引擎的结合。它将日志文件视作数据库表格,通过 SQL 查询语言来对日志数据进行操作。这使得用户可以像使用关系数据库一样,通过 SELECT、WHERE、GROUP BY 等 SQL 语句来分析和处理日志。以下是其底层原理的详细解释:
1. 日志解析引擎
Log Parser Lizard 的核心原理之一是日志解析引擎,它能够处理多种日志格式,包括但不限于:
文本日志:如 Apache、IIS、Windows 系统日志等。
结构化日志:如 JSON、XML、CSV 格式的日志文件。
非结构化日志:对普通文本或按行分隔的日志进行处理。
解析流程:
输入解析:工具首先对日志文件进行解析,识别日志的结构。例如,时间戳、请求路径、错误代码等字段。
字段提取:通过正则表达式或自定义格式,将日志中的每一条信息转化为标准的列数据。
数据映射:日志字段映射到 SQL 查询中的虚拟表格列,最终这些数据被呈现为 SQL 表格,可以通过 SQL 语句进行查询和处理。
2. SQL 查询引擎
Log Parser Lizard 将日志数据视为数据库表格,因此可以通过 SQL 查询语言进行分析。它的 SQL 查询引擎支持基本的 SQL 操作,如:
SELECT:选择特定的列或记录。
WHERE:用于筛选满足条件的日志数据。
GROUP BY:对日志数据进行分组,并支持对分组后的数据进行聚合(如计数、求和、平均值等)。
ORDER BY:对结果进行排序。
HAVING:对分组后的数据进行筛选。
3. 数据存储与查询优化
Log Parser Lizard 在底层并不将日志数据存储到数据库中,而是将其在内存中转化为表格形式来进行处理。这种方法减少了 I/O 操作,提高了分析效率。它还具有一定的查询优化能力,能够根据查询语句的复杂度选择合适的执行路径。
内存操作:数据会临时加载到内存中进行处理,这使得查询速度更快,尤其是在处理大规模日志时。
索引优化:某些常用字段(如时间戳、IP 地址)会生成索引,提高查询效率,尤其在大量数据中能加速检索过程。
4. 正则表达式支持
Log Parser Lizard 支持正则表达式,这使得它能够对日志中的复杂数据进行匹配和提取。正则表达式可以在日志分析中发挥重要作用,尤其是当日志的格式不统一或包含特定的错误模式时。
灵活过滤:用户可以通过正则表达式自定义复杂的过滤条件。
数据提取:通过正则表达式提取复杂字段,例如从一行文本中提取 IP 地址、请求路径、响应时间等信息。
5. 数据可视化
Log Parser Lizard 内置数据可视化模块,支持通过图形界面展示查询结果。它能够将 SQL 查询结果转化为各种图表,包括柱状图、饼图、折线图等。可视化引擎底层通常会利用图形库(如 D3.js 或其他图表库)来生成动态和交互式的可视化结果。
6. 实时数据处理
Log Parser Lizard 支持对实时日志流的处理,即使是不断生成的日志文件也可以进行实时监控与分析。这是通过文件轮询或事件监听机制来实现的。当日志文件发生变化时,系统会自动重新解析并更新分析结果。
文件监控:实时监听日志文件的变化,并在日志内容更新时触发分析任务。
流式数据处理:工具会逐行解析新加入的日志数据,并进行相应的 SQL 查询。
7. 自动化与脚本支持
Log Parser Lizard 提供了自动化任务功能,可以设置定时任务或脚本任务来自动执行日志分析。这是通过集成的调度系统和脚本引擎实现的,用户可以编写批处理或 PowerShell 脚本,并在指定的时间周期内自动运行日志分析任务。
脚本接口:支持 PowerShell、批处理脚本和其他自动化工具的集成,便于将日志分析任务与现有的自动化流程结合。
定时任务:可以通过系统的调度程序设置定期任务,自动分析日志文件并生成报告。
8. 数据库集成与支持
Log Parser Lizard 也能够与外部数据库集成,通过 SQL 查询将日志数据与其他数据库中的信息结合进行分析。这种跨数据源的能力使得它能够在更复杂的数据环境中进行日志分析。
SQL Server、MySQL、Oracle 等数据库支持:可以将日志数据与数据库中的表格进行 JOIN 操作,以实现更全面的数据分析。
数据输出与导出:分析结果可以导出为 CSV、Excel、HTML 等格式,方便后续处理或报告生成。
Log Parser Lizard 的底层原理是将日志文件中的信息抽象成数据库表格,并通过 SQL 查询来进行分析。它结合了日志解析引擎、SQL 查询引擎、正则表达式处理、数据可视化以及自动化等技术,使得日志分析变得更加高效和灵活。无论是处理本地日志还是远程日志,Log Parser Lizard 都能提供强大的分析能力,适应不同的需求和数据格式。
Log Parser Lizard 是一款功能强大的日志分析工具,其架构设计旨在处理各种类型的日志数据,并将其转化为可查询的结构化数据。Log Parser Lizard 的架构包含多个层次和组件,协同工作以提供高效的日志分析功能。以下是 Log Parser Lizard 架构的详细分析:
1. 用户界面层 (UI Layer)
用户界面层是 Log Parser Lizard 与用户交互的最直接部分。它提供了一个图形化界面,使用户能够以直观的方式加载、分析和可视化日志数据。主要组件包括:
查询编辑器:用于编写 SQL 查询,支持语法高亮和自动补全功能,方便用户编写复杂的查询语句。
结果展示窗口:显示查询结果,可以是表格、图表等形式。
日志文件加载器:允许用户选择并加载不同类型的日志文件,支持批量加载。
数据可视化模块:将 SQL 查询的结果转化为图形和图表,支持多种图表类型(如柱状图、折线图、饼图等),帮助用户更直观地理解分析结果。
2. 数据解析层 (Parsing Layer)
数据解析层负责解析原始日志文件,将其转化为结构化数据。不同格式的日志文件(如 Apache、IIS、Windows 系统日志、JSON、XML 等)需要通过不同的解析方式进行处理。
日志格式识别:Log Parser Lizard 能够自动识别并支持多种日志格式(如纯文本格式、JSON、CSV、XML 等)。它可以解析标准化的日志格式,也能处理自定义的日志格式。
字段提取与标准化:通过正则表达式、模式匹配等方式,提取日志中的关键信息,如时间戳、IP 地址、请求路径、状态码等,并将其映射到结构化数据字段中。
数据转换:在解析过程中,原始日志数据被转化为标准化的列和行格式,便于后续的 SQL 查询和分析。
3. SQL 查询引擎 (SQL Query Engine)
Log Parser Lizard 的核心是其 SQL 查询引擎,允许用户像操作关系数据库一样进行日志数据分析。SQL 引擎的作用是处理用户的 SQL 查询,并对解析后的日志数据执行查询操作。
SQL 语法支持:Log Parser Lizard 支持常见的 SQL 查询操作,包括
SELECT、FROM、WHERE、GROUP BY、ORDER BY等常用功能,甚至支持JOIN等高级操作。虚拟表格:解析后的日志数据会被转换为内存中的虚拟表格。每个日志文件或日志流可以视为一个虚拟表,用户可以对这些表格进行 SQL 查询操作。
查询优化:引擎在执行查询时,会根据查询语句的复杂度自动选择合适的优化策略,例如使用索引、限制内存使用等方式来提高查询性能。
4. 数据存储与内存管理层 (Storage & Memory Management)
Log Parser Lizard 并不直接使用传统的关系数据库来存储日志数据,而是将日志数据存储在内存中,以便快速访问和分析。这一层主要负责数据的存储、缓存和内存管理。
内存中的数据表:日志数据在解析后存储在内存中的表格结构中。数据表可以动态加载,随着日志的增加或查询的变化而调整。
内存优化:为避免内存溢出和提高性能,Log Parser Lizard 会智能地管理内存使用,例如缓存频繁访问的数据,或者按需加载数据。
数据持久化与导出:虽然 Log Parser Lizard 主要依赖内存,但也支持将查询结果导出为 CSV、Excel 或 HTML 等格式,以便保存和进一步处理。
5. 正则表达式引擎 (Regex Engine)
正则表达式引擎在 Log Parser Lizard 中扮演着重要角色,特别是在解析日志数据时。它允许用户通过正则表达式灵活地提取和匹配日志中的特定字段或模式。
数据提取:用户可以使用正则表达式提取复杂字段,如从一行日志中提取时间戳、IP 地址、请求路径等。
高级过滤:在查询过程中,用户可以使用正则表达式进行数据过滤,以识别特定的日志事件或异常情况。
灵活性:正则表达式的支持让 Log Parser Lizard 在面对各种格式的日志时,能提供更高的灵活性和适应性。
6. 数据可视化与报告生成层 (Visualization & Reporting Layer)
Log Parser Lizard 提供强大的数据可视化功能,帮助用户更直观地理解分析结果。
图表与报表生成:支持多种图表类型,如柱状图、饼图、折线图等,可以将 SQL 查询结果以图形方式呈现出来。
交互式报表:支持生成交互式报表,用户可以动态调整视图或过滤条件,实时查看数据变化。
导出功能:可将生成的图表和报表导出为多种格式,如 PDF、CSV、Excel 或 HTML,方便与团队共享或用于报告展示。
7. 实时监控与数据流处理 (Real-Time Monitoring & Data Streaming)
Log Parser Lizard 支持实时日志监控和数据流处理,能够处理不断更新的日志数据。
实时文件监控:工具可以监控指定的日志文件或目录,并在日志文件更新时自动解析和分析新数据。
流式数据处理:对于实时生成的日志流,Log Parser Lizard 会逐行解析并执行 SQL 查询,实时提供分析结果。
警报与通知:可以设置警报规则,当日志中出现特定事件或异常时,系统会自动通知用户。
8. 自动化与脚本支持 (Automation & Scripting)
Log Parser Lizard 提供强大的自动化支持,允许用户通过脚本自动执行日志分析任务。
定时任务:用户可以设置定时任务,自动定期分析日志并生成报表。
脚本支持:支持 PowerShell、批处理脚本和其他自动化脚本,可以通过命令行执行日志分析任务,方便与其他自动化流程结合。
9. 数据库集成与外部数据源支持 (Database Integration & External Data Sources)
Log Parser Lizard 能与外部数据库和数据源集成,将日志数据与其他数据进行结合分析。
SQL 数据库集成:支持与 SQL Server、MySQL、Oracle 等关系数据库集成,用户可以将日志数据与数据库中的其他表格联合查询。
跨数据源分析:用户可以将日志数据与其他来源的数据(例如系统监控数据、性能数据等)进行联合分析,获得更全面的洞察。
Log Parser Lizard 的架构是由多个独立但协同工作的层次组成的。用户通过图形化界面输入 SQL 查询,日志数据通过解析引擎转化为结构化数据后,通过 SQL 引擎执行查询。同时,正则表达式引擎提供灵活的数据提取能力,数据可视化层帮助用户更直观地理解分析结果,实时监控和自动化脚本功能进一步提高了其应用的灵活性和自动化水平。整体架构旨在提供高效、灵活和可扩展的日志分析解决方案。
Log Parser Lizard 是一个非常强大的日志分析工具,它提供了一个图形化用户界面来简化日志数据的处理、查询和分析。为了更好地理解 Log Parser Lizard 的框架,我们可以从以下几个方面来分析其架构:用户界面层、数据解析层、SQL 查询引擎、内存管理层、正则表达式引擎、数据可视化与报告生成层、实时监控与自动化支持等。以下是 Log Parser Lizard 框架的详细分析:
1. 用户界面层 (UI Layer)
Log Parser Lizard 提供了直观的图形化界面,用户可以通过该界面加载日志文件、编写查询、查看结果等操作。这个层次使得复杂的日志分析工作变得更加容易。
查询编辑器:用户通过编辑器编写 SQL 查询语句,并查看查询结果。支持语法高亮和自动补全功能。
结果展示窗口:查询结果展示区域,可以以表格、图表等多种形式显示结果。
文件加载器:支持批量导入和加载多种类型的日志文件。
数据可视化:图形化展示查询结果,帮助用户更直观地理解数据分析的结论。
2. 数据解析层 (Parsing Layer)
该层负责解析不同格式的日志文件,将其转换为结构化数据。Log Parser Lizard 能够处理各种格式的日志文件,并将日志内容标准化为统一的数据结构,方便后续的查询分析。
支持多种日志格式:包括 Apache、IIS、Windows 系统日志、JSON、CSV、XML 等多种日志格式。
字段提取与标准化:从原始日志中提取关键信息,如时间戳、IP 地址、请求路径等,并将其转化为结构化的字段,确保后续 SQL 查询可以无缝操作。
模式匹配:支持基于正则表达式的日志字段提取,确保即便是自定义的日志格式也能被正确解析。
3. SQL 查询引擎 (SQL Query Engine)
Log Parser Lizard 的 SQL 查询引擎是该工具的核心组件。它支持对解析后的日志数据进行 SQL 查询,允许用户像操作数据库一样执行查询。
SQL 支持:Log Parser Lizard 支持 SQL 语法的常见操作,如
SELECT、FROM、WHERE、GROUP BY、ORDER BY等。虚拟表格:将解析后的日志数据加载到内存中的虚拟表格中,用户可以在这些表格上执行查询。
查询优化:查询引擎会根据查询的复杂度自动选择合适的优化策略,保证查询性能。
4. 内存管理层 (Memory Management)
为了提高日志处理的效率,Log Parser Lizard 将日志数据保存在内存中进行快速查询。此层的主要任务是对内存中的数据进行高效的存储与管理。
内存表格:所有的日志数据在解析后会存储在内存中的虚拟表格中,能够在不依赖外部数据库的情况下进行快速处理。
缓存机制:通过智能缓存机制来提高查询的效率,减少内存消耗,并避免不必要的重复计算。
数据持久化:尽管 Log Parser Lizard 主要使用内存存储数据,但它也支持将查询结果导出为 CSV、Excel 等格式,便于数据持久化和后续处理。
5. 正则表达式引擎 (Regex Engine)
Log Parser Lizard 强大的正则表达式引擎允许用户灵活地解析和提取日志中的特定数据字段。
数据提取:正则表达式用于从原始日志数据中提取时间戳、IP 地址、URL 等字段。
高级过滤:在 SQL 查询中,用户可以使用正则表达式过滤特定的日志行或字段,方便进行异常检测和模式匹配。
灵活性与扩展性:用户可以根据需要创建自定义的正则表达式,灵活适配各种不同格式的日志文件。
6. 数据可视化与报告生成层 (Visualization & Reporting Layer)
Log Parser Lizard 提供了强大的数据可视化功能,以帮助用户直观地分析和展示查询结果。
图表生成:支持生成各种类型的图表,如柱状图、折线图、饼图等,用户可以将 SQL 查询结果转化为图形展示。
动态报表:用户可以生成交互式报表,可以实时查看和过滤查询结果,并生成可共享的报告。
报告导出:生成的图表和报表可以导出为 PDF、CSV、Excel 等格式,方便进行分享和存档。
7. 实时监控与自动化支持 (Real-Time Monitoring & Automation)
Log Parser Lizard 还支持实时日志监控和自动化任务,能够不断处理和分析更新中的日志数据。
实时文件监控:支持监控指定目录下的日志文件,当文件更新时,Log Parser Lizard 会自动加载新日志并进行解析。
流式数据处理:可以实时处理流式日志数据,逐行分析和查询,不需要等待整个日志文件加载完成。
自动化任务:支持定时任务和脚本,用户可以设置周期性任务自动执行日志分析,生成定期报告。
8. 脚本支持与定制化 (Scripting & Customization)
Log Parser Lizard 提供了脚本支持,使得用户能够通过脚本实现更复杂的日志分析流程。
PowerShell / 批处理脚本:支持 PowerShell 脚本和批处理脚本,用户可以自动化执行日志查询任务。
定制化查询:用户可以根据自己的需求,定制查询逻辑和处理流程,实现特定场景下的日志分析。
9. 外部数据源集成 (Database Integration & External Sources)
Log Parser Lizard 不仅仅是一个单独的日志分析工具,它还能够与外部数据库进行集成,帮助用户进行更复杂的数据关联分析。
SQL 数据库集成:Log Parser Lizard 支持与 SQL Server、MySQL、Oracle 等数据库进行集成,允许将日志数据与数据库中的其他表格联合查询。
跨数据源分析:用户可以将日志数据与其他数据源(如系统监控数据、性能数据等)进行联合分析,获得更加全面的业务洞察。
Log Parser Lizard 的框架以多层次的设计为基础,涵盖了从数据解析到查询引擎、从内存管理到数据可视化等各个方面。这些组件协同工作,提供了一个高效、灵活且可扩展的日志分析平台。无论是处理标准日志文件,还是执行复杂的 SQL 查询,Log Parser Lizard 都能够高效地提供日志分析解决方案。
Log Parser Lizard 初级使用教程大纲
Log Parser Lizard 是一款强大的日志分析工具,能够解析并分析不同格式的日志文件,例如 IIS 日志、事件日志、Web 服务器日志等。该工具为用户提供了一个可视化的界面,使得分析和查询日志变得更加简单直观。
以下是一个 Log Parser Lizard 初级使用教程的大纲,旨在帮助新手用户快速入门并掌握基本功能。
1. 引言
1.1 什么是 Log Parser Lizard?
概述:介绍 Log Parser Lizard 的基本功能和用途。
支持的日志格式:IIS 日志、CSV、XML、事件日志、Windows 应用程序日志等。
1.2 为什么使用 Log Parser Lizard?
强大的查询能力
图形化界面简化使用
支持 SQL 查询语言进行日志分析
2. 安装与配置
2.1 下载与安装
从官网或其他平台下载 Log Parser Lizard
安装步骤:安装路径、安装依赖等
2.2 配置环境
配置 Log Parser Lizard 连接不同的数据源
设置 Log Parser Lizard 与数据库的连接(如果有)
3. Log Parser Lizard 界面概览
3.1 主界面介绍
文件菜单(新建查询、打开查询等)
工具栏功能(查询、执行、查看结果等)
左侧导航栏(日志文件选择、数据源设置等)
查询窗口(编写和执行 SQL 查询)
结果面板(查询结果展示)
3.2 关键功能介绍
SQL 查询编辑器
结果导出:如何导出查询结果为 CSV、Excel 或其他格式
数据过滤与排序:如何使用查询语句筛选和排序日志数据
4. Log Parser Lizard 的基础操作
4.1 打开日志文件
如何选择并打开日志文件(如 IIS 日志、应用程序日志等)
支持的文件格式和如何识别日志文件
4.2 编写 SQL 查询
查找特定时间段的日志
查询特定 IP 的访问日志
按 URL 进行流量统计
SELECT 语句的使用
FROM 语句指定数据源
WHERE 语句进行数据筛选
GROUP BY 进行分组统计
ORDER BY 排序
基本的 SQL 查询语法
常用 SQL 查询示例:
4.3 执行查询
如何执行查询并查看结果
查询执行过程中的常见问题和解决方法
5. 日志数据分析与可视化
5.1 数据聚合与汇总
使用 SQL 聚合函数(如 COUNT、SUM、AVG)进行日志分析
按时间、IP 地址、状态码等进行数据汇总
5.2 可视化数据
如何将分析结果可视化(例如:生成图表、折线图等)
支持的图表类型(柱状图、饼图、折线图等)
5.3 导出数据
导出查询结果为 CSV、Excel 或其他格式
使用图表导出报告
6. 进阶使用技巧
6.1 使用正则表达式
如何在 Log Parser Lizard 中使用正则表达式进行日志筛选
正则表达式常见模式
6.2 调试与优化查询
如何调试查询语法
优化查询以提高执行效率
6.3 自动化任务
如何创建并保存常用查询
使用 Log Parser Lizard 执行定期任务(如自动生成报告)
7. 常见问题与解决方案
7.1 无法加载日志文件的解决方法
文件格式不支持或文件损坏
7.2 查询结果不准确
数据格式问题、查询语法错误等
7.3 性能优化
如何优化查询执行速度,避免过长时间的查询
8. 总结与进阶学习
8.1 Log Parser Lizard 的高级功能概述
更复杂的 SQL 查询、联合查询等
8.2 学习资源
推荐的教程、文档和社区资源
8.3 实际应用案例
实际使用场景中的日志分析示例
附录:常用 SQL 查询示例
查询特定日期范围的访问日志:
sqlCopy CodeSELECT COUNT(*) AS Hits, date FROM [log_file] WHERE date BETWEEN '2023-01-01' AND '2023-01-31'GROUP BY dateORDER BY date;
查询最常访问的 IP 地址:
sqlCopy CodeSELECT ClientIP, COUNT(*) AS HitCount FROM [log_file]GROUP BY ClientIPORDER BY HitCount DESC LIMIT 10;
查询某个 URL 的访问情况:
sqlCopy CodeSELECT csUriStem, COUNT(*) AS HitCount FROM [log_file]WHERE csUriStem = '/specific-page'GROUP BY csUriStem;
通过此教程大纲,初学者能够快速了解 Log Parser Lizard 的基础使用,掌握常用查询技能,进而在日常工作中运用这一工具进行日志数据分析。
Log Parser Lizard 中级使用教程大纲
Log Parser Lizard 是一个功能强大的日志分析工具,支持多种日志格式,并能够通过 SQL 查询语言高效地处理和分析数据。在中级教程中,我们将深入探讨如何优化查询、利用高级功能进行数据分析,并实现自动化任务和复杂的可视化报表。
以下是 Log Parser Lizard 中级使用教程的大纲,帮助用户提升对该工具的理解,解决复杂的日志分析问题。
1. 引言
1.1 复习 Log Parser Lizard 的基本功能
简要回顾基本使用(如何导入文件、基本查询)
本教程的目标:深入探讨 Log Parser Lizard 的中级功能
1.2 为什么学习中级功能?
处理更复杂的查询
自动化与定期报告
深入分析与可视化
2. 高级 SQL 查询
2.1 多表查询与联合查询(JOIN)
sqlCopy CodeSELECT A.ClientIP, A.csUriStem, COUNT(B.status) AS ErrorCountFROM [access_log] A LEFT JOIN [error_log] B ON A.ClientIP = B.ClientIPWHERE B.status = '404'GROUP BY A.ClientIP, A.csUriStemORDER BY ErrorCount DESC;
内连接 (INNER JOIN) 和外连接 (LEFT JOIN)
示例:结合访问日志与错误日志,查询特定 URL 上的 404 错误
2.2 子查询与嵌套查询
sqlCopy CodeSELECT csUriStem, COUNT(*) AS VisitCountFROM [log_file]WHERE csUriStem IN (SELECT csUriStem FROM [log_file] GROUP BY csUriStem HAVING COUNT(*) > 100)GROUP BY csUriStemORDER BY VisitCount DESC;
使用子查询进行更复杂的数据筛选
示例:查询访问次数大于某一特定值的 URL
2.3 聚合函数与窗口函数
sqlCopy CodeSELECT csUriStem, COUNT(*) AS VisitCount, SUM(CASE WHEN status = '200' THEN 1 ELSE 0 END) AS SuccessCountFROM [log_file]GROUP BY csUriStemORDER BY VisitCount DESC;
使用
COUNT(),SUM(),AVG()等函数进行聚合分析窗口函数的应用:按时间段分析访问趋势
2.4 复杂的条件查询与正则表达式
sqlCopy CodeSELECT ClientIP, csUriStemFROM [log_file]WHERE csUriStem LIKE '%/error%' AND ClientIP REGEXP '^[0-9]+\.[0-9]+\.[0-9]+\.[0-9]+$';
利用
LIKE、REGEXP等进行模糊匹配正则表达式应用实例:匹配特定格式的日志条目
3. 高级数据分析与聚合
3.1 按时间进行分组与统计
sqlCopy CodeSELECT FORMAT_TIMESTAMP(date, 'YYYY-MM-DD') AS Day, COUNT(*) AS HitsFROM [log_file]GROUP BY DayORDER BY Day;
使用时间戳字段进行日、周、月等时间粒度的分组
示例:按天统计访问量
3.2 使用
HAVING进行条件过滤sqlCopy CodeSELECT csUriStem, COUNT(*) AS VisitCount FROM [log_file] GROUP BY csUriStem HAVING COUNT(*) > 1000ORDER BY VisitCount DESC;
在聚合后的结果上进一步进行过滤
示例:筛选出访问次数超过某个阈值的 URL
3.3 计算复杂指标
sqlCopy CodeSELECT ClientIP, AVG(duration) AS AvgDurationFROM [log_file]GROUP BY ClientIPORDER BY AvgDuration DESC;
计算页面停留时长、用户留存率等指标
示例:计算某段时间内每个用户的平均访问时长
4. 高级日志分析
4.1 日志数据清洗与预处理
清理缺失值、无效数据
将日志数据转换为结构化格式,去除噪声
4.2 错误日志分析
sqlCopy CodeSELECT status, COUNT(*) AS ErrorCountFROM [error_log]GROUP BY statusORDER BY ErrorCount DESC;
分析应用错误或服务器错误
示例:查找发生最多的错误类型
4.3 热点分析与流量趋势
sqlCopy CodeSELECT csUriStem, COUNT(*) AS HitCount, AVG(duration) AS AvgDurationFROM [log_file]GROUP BY csUriStemORDER BY HitCount DESC, AvgDuration DESC;
热点页面流量分析
按流量和响应时间分析高负载页面
5. 自动化与定期任务
5.1 定期任务与自动化执行
使用 Windows 任务计划程序定期执行 Log Parser Lizard 查询
设置 Log Parser Lizard 执行并将结果导出
5.2 定制化报告生成
bashCopy Codelogparser "SELECT csUriStem, COUNT(*) AS HitCount FROM 'C:\logs\access.log' GROUP BY csUriStem" -o:csv -q:off > "C:\reports\monthly_report.csv"
创建自动化脚本生成定期日志分析报告
示例:生成每月流量报告
5.3 邮件通知与结果发送
设置自动化脚本发送报告通过电子邮件
6. 可视化与图表
6.1 自定义图表
创建自定义的可视化报表(柱状图、折线图、饼图等)
示例:创建一个访问流量趋势图
6.2 使用外部工具进行可视化
将 Log Parser Lizard 查询结果导入 Power BI、Excel 等工具进行高级可视化
导出查询结果为 CSV 或 Excel 格式
6.3 配置仪表板
设置实时监控仪表板展示关键指标
使用 Log Parser Lizard 进行数据准备并配合外部工具实时展示
7. 性能优化
7.1 优化大数据量查询
使用合适的索引与分区
优化 SQL 查询,避免不必要的全表扫描
7.2 查询缓存与并行处理
使用查询缓存提高查询速度
多线程查询和数据分片的应用
7.3 减少内存占用与执行时间
调整查询语句结构,减少内存消耗
对大规模日志文件进行分割处理
8. 常见问题与高级调试
8.1 复杂查询错误与调试
常见 SQL 错误类型与解决方法
如何调试和优化查询语句
8.2 资源瓶颈与系统配置
分析系统资源使用情况(内存、CPU、磁盘 I/O)
如何调整 Log Parser Lizard 的配置,以适应大数据集
8.3 日志格式问题与转换
如何应对不同日志格式之间的转换问题
处理格式不统一的日志文件
9. 总结与进阶资源
9.1 Log Parser Lizard 高级功能概述
更复杂的分析方法(多层嵌套查询、复杂条件)
实时日志监控与大数据集分析
9.2 推荐的进一步学习资源
高级文档、开发者社区和论坛
学习 SQL 的其他高级技巧
9.3 实际应用案例
结合实际的业务场景展示如何在 Log Parser Lizard 中进行复杂分析
附录:常用 SQL 查询示例
查找过去 30 天最活跃的 IP 地址:
sqlCopy CodeSELECT ClientIP, COUNT(*) AS VisitCountFROM [log_file]WHERE date > GETDATE() - 30GROUP BY ClientIPORDER BY VisitCount DESC;
分析错误日志并计算每种错误的出现次数:
sqlCopy CodeSELECT error_code, COUNT(*) AS ErrorCountFROM [error_log]GROUP BY error_codeORDER BY ErrorCount DESC;
通过本教程,用户可以学会如何进行更复杂的日志分析,优化查询性能,并使用 Log Parser Lizard 执行自动化任务和高级报表生成,最终为系统运维、性能优化等工作提供有力
Log Parser Lizard 高级使用教程大纲
Log Parser Lizard 是一个功能强大的日志分析工具,支持通过 SQL 查询语言对不同格式的日志文件进行高效处理。在高级教程中,我们将深入探讨如何充分利用 Log Parser Lizard 的高级功能,进行复杂的数据分析,提升性能,并实现自动化报告和可视化输出。
1. 引言
1.1 Log Parser Lizard 简介
Log Parser Lizard 的特点与优势
高级功能的应用场景(如大规模数据分析、实时监控、复杂日志分析等)
1.2 学习目标
掌握更复杂的 SQL 查询技巧
优化 Log Parser Lizard 性能
实现自动化与定期任务
数据可视化与报表生成
2. 高级 SQL 查询技巧
2.1 多表查询与 JOIN 操作
sqlCopy CodeSELECT A.ClientIP, A.csUriStem, B.status, COUNT(*)FROM [access_log] A INNER JOIN [error_log] B ON A.ClientIP = B.ClientIP AND A.date = B.dateWHERE B.status = '500'GROUP BY A.ClientIP, A.csUriStem, B.status;
内连接、外连接、交叉连接的使用
使用 JOIN 查询合并多个日志文件(如访问日志与错误日志)
示例:查找在同一时间段内有访问记录和错误日志的用户
2.2 子查询与嵌套查询
sqlCopy CodeSELECT csUriStem, COUNT(*) AS VisitCountFROM [access_log]WHERE csUriStem IN (SELECT csUriStem FROM [access_log] GROUP BY csUriStem HAVING COUNT(*) > 100)GROUP BY csUriStem;
使用子查询来处理复杂的筛选和聚合
示例:查找访问次数超过 100 次的 URL
2.3 窗口函数与高级聚合
sqlCopy CodeSELECT ClientIP, csUriStem, COUNT(*) AS VisitCount, ROW_NUMBER() OVER (ORDER BY COUNT(*) DESC) AS Rank FROM [access_log] GROUP BY ClientIP, csUriStem;
使用
ROW_NUMBER()、RANK()、DENSE_RANK()等窗口函数示例:计算每个用户的访问排名
2.4 正则表达式与复杂匹配
sqlCopy CodeSELECT ClientIP, csUriStemFROM [access_log]WHERE csUriStem REGEXP '^/api/.*';
使用
REGEXP和正则表达式进行复杂模式匹配示例:匹配所有访问特定路径的日志记录
2.5 日期与时间的高级处理
sqlCopy CodeSELECT FORMAT_TIMESTAMP(date, 'YYYY-MM-DD HH') AS Hour, csUriStem, COUNT(*) AS VisitCountFROM [access_log]GROUP BY Hour, csUriStemORDER BY Hour;
使用日期和时间函数进行复杂的时间范围查询和聚合
示例:按小时统计每个页面的访问量
3. 日志分析中的高级技术
3.1 日志数据清洗与格式转换
使用 Log Parser Lizard 对日志数据进行清洗(如去除无效数据、填补缺失值)
将不规则格式的日志数据转化为结构化数据
3.2 错误日志的高级分析
sqlCopy CodeSELECT error_code, COUNT(*) AS ErrorCountFROM [error_log]GROUP BY error_codeORDER BY ErrorCount DESC;
分析常见的错误类型及其分布
示例:按错误类型统计每种错误的发生次数
3.3 热点分析与流量趋势
sqlCopy CodeSELECT csUriStem, COUNT(*) AS VisitCountFROM [access_log]WHERE date > GETDATE() - 7GROUP BY csUriStemORDER BY VisitCount DESC;
使用聚合函数分析热点页面与流量趋势
示例:查找过去一周内流量最大的页面
3.4 页面响应时间与性能分析
sqlCopy CodeSELECT csUriStem, AVG(duration) AS AvgDuration, MAX(duration) AS MaxDurationFROM [access_log]GROUP BY csUriStemORDER BY MaxDuration DESC;
分析页面响应时间,找出性能瓶颈
示例:按 URL 查询响应时间的平均值和最大值
4. 自动化与定期任务
4.1 定期任务的创建与管理
示例:每天 12 点运行一个日志分析脚本
bashCopy Codelogparser "SELECT * FROM 'C:\logs\access.log' WHERE date > GETDATE() - 1" -o:csv > 'C:\reports\daily_report.csv'
使用 Windows 任务计划程序(Task Scheduler)定期运行 Log Parser Lizard 查询
设置脚本在指定时间间隔自动执行
4.2 自动化报告生成
示例:使用 PowerShell 发送报告
powershellCopy CodeSend-MailMessage -From "admin@example.com" -To "recipient@example.com" -Subject "Daily Log Report" -Body "Please find the daily log report attached." -Attachments "C:\reports\daily_report.csv" -SmtpServer "smtp.example.com"
生成定期报告并自动发送到指定邮箱
使用 Log Parser Lizard 导出数据为 CSV、Excel 或 HTML 格式,并通过脚本发送报告
4.3 日志监控与实时通知
sqlCopy CodeSELECT COUNT(*) AS ErrorCount FROM [error_log] WHERE status = '500' AND date > GETDATE() - 1 HAVING COUNT(*) > 10;
配置 Log Parser Lizard 进行实时日志监控,并触发告警(如 HTTP 500 错误超过阈值)
示例:在日志中出现特定错误时触发通知
5. 数据可视化与报表
5.1 使用 Log Parser Lizard 的内建图表功能
创建柱状图、折线图、饼图等简单可视化图表
示例:按访问量绘制页面流量柱状图
5.2 将 Log Parser Lizard 数据导入外部工具
将 Log Parser Lizard 查询结果导入 Power BI、Excel、Tableau 等工具进行高级数据可视化
示例:将查询结果导出为 CSV 文件,并导入 Power BI 生成动态仪表盘
5.3 定制化报告与仪表板
创建自定义报表模板,支持按需生成不同格式的报告(HTML、PDF、CSV)
使用 Log Parser Lizard 执行查询,并通过外部工具展示实时数据
6. 性能优化与调优
6.1 优化查询效率
sqlCopy CodeSELECT ClientIP, COUNT(*) AS VisitCountFROM [access_log]WHERE date > GETDATE() - 30GROUP BY ClientIP;
避免全表扫描,使用合适的索引和 WHERE 子句优化查询
示例:使用 WHERE 子句减少查询数据量
6.2 数据分片与并行处理
对于大规模数据集,使用数据分片(Sharding)与并行查询提高效率
设置 Log Parser Lizard 分片处理多个日志文件
6.3 内存与资源管理
使用内存优化技巧,如减少不必要的字段选择、控制查询结果大小
分析查询资源消耗,并调整查询结构
7. 高级调试与问题排查
7.1 调试复杂查询
使用 Log Parser Lizard 的调试模式查找查询中的潜在问题
常见的 SQL 错误及解决方法
7.2 系统资源监控与优化
监控 Log Parser Lizard 查询时的 CPU、内存、磁盘 I/O 使用情况
优化查询策略,避免对系统资源造成过大负担
7.3 日志格式与数据不一致问题
处理日志文件格式不一致或损坏的情况
使用 Log Parser Lizard 数据清洗功能解决数据质量问题
8. 总结与进阶学习资源
8.1 Log Parser Lizard 高级功能回顾
复习高效查询、自动化、数据可视化等高级技能
结合实际案例进行总结
8.2 进阶学习资源与社区
推荐的学习资源:在线文档、书籍、技术论坛、GitHub 项目等
加入 Log Parser Lizard 用户社区
Log Parser Lizard 专家级使用教程大纲
引言
目标:帮助用户全面掌握 Log Parser Lizard 的高级功能和使用技巧,以便进行高效的日志分析和查询。
预备知识:基础的 SQL 查询语言知识,日志文件结构与格式理解,Log Parser Lizard 基础使用。
第一部分:Log Parser Lizard 概述
Log Parser Lizard 简介
Log Parser Lizard 的定位与功能
适用的日志文件格式与应用场景
主要组件与架构概述
安装与配置
安装步骤与环境配置
系统要求与依赖
常见问题及解决方法
第二部分:日志数据解析与导入
支持的日志格式
常见日志格式:Apache, IIS, Windows 事件日志, JSON, CSV, XML 等
自定义日志格式解析
日志导入与管理
导入单个和批量日志文件
文件夹监控与实时数据加载
日志文件的自动归档与清理策略
日志解析与字段提取
内置解析器与正则表达式配置
自定义字段提取与数据映射
解析多行日志记录(例如堆栈跟踪、事件日志)
第三部分:SQL 查询引擎进阶
高级 SQL 查询技术
高级查询功能:子查询、连接查询、窗口函数
聚合函数与分组操作
条件查询:复杂的 WHERE 子句与正则表达式
SQL 优化与执行计划分析
数据类型与转换
数据类型映射与转换
时间戳处理与格式化
数据合并与去重
虚拟表与数据集操作
创建虚拟表格
使用
WITH子句创建临时查询结果集联合查询与表之间的复杂连接操作
第四部分:正则表达式与日志数据提取
正则表达式基础
正则表达式语法与常见用法
日志数据中常见模式的匹配技巧
正则表达式在查询中的应用
在 SQL 查询中使用正则表达式进行字段过滤与提取
高效的正则表达式编写技巧与优化
自定义日志字段提取
如何使用正则表达式从日志中提取特定信息
多层次数据提取与处理技巧
第五部分:内存管理与性能优化
内存管理架构
内存中的虚拟表格存储与管理
内存使用的优化技巧:缓存机制与数据分页
查询性能优化
查询优化策略:如何处理大规模日志文件
使用索引与缓存提高查询速度
复杂查询与大数据集的处理技巧
并行处理与批量查询
如何利用多核处理器优化查询性能
批量查询的优化:分批次处理与异步操作
第六部分:数据可视化与报告生成
图表与报告设计
支持的图表类型:折线图、柱状图、饼图等
从 SQL 查询结果生成动态图表
多图表布局与交互式图形界面
报表自动化与定制
定期生成报表与自动化任务设置
报表定制化:添加过滤条件、格式调整
报告输出格式:PDF、Excel、CSV 等
实时数据可视化
实时监控与动态展示
使用仪表板进行多维数据分析
第七部分:实时日志分析与自动化
实时数据监控与处理
配置实时日志监控任务
流式数据处理与分析
设置警报与自动通知机制
定时任务与自动化脚本
使用批处理脚本与 PowerShell 自动化查询任务
设置周期性任务与定时报告
与其他工具的集成:API 接口与外部系统
第八部分:与外部数据源的集成
数据库集成
与 SQL Server、MySQL、PostgreSQL 等数据库的连接配置
联合查询:结合日志数据与数据库表格
数据同步与批量导入操作
跨平台数据分析
将日志数据与其他外部数据源(如系统监控数据、性能数据)结合
数据整合与多数据源分析策略
外部 API 调用
使用 Log Parser Lizard 调用外部 API 接口进行数据采集与分析
与云端服务的集成:AWS、Azure、Google Cloud 等
第九部分:脚本与高级定制化
PowerShell 与批处理脚本
如何编写 PowerShell 脚本自动化日志分析流程
批处理文件的使用与调度
高级查询脚本
脚本中的变量与动态查询
自定义查询模板与查询库
定制化插件开发
使用 Log Parser Lizard 的 API 开发定制插件
扩展 Log Parser Lizard 功能,支持新的日志格式与数据处理方式
第十部分:常见问题与最佳实践
常见错误与解决方案
错误日志分析:如何处理查询失败、内存不足等问题
排查查询性能问题与日志解析问题
最佳实践
如何构建高效的日志分析流程
管理大规模日志数据集的技巧
多用户协作与权限管理
总结
Log Parser Lizard 的优势与局限
进一步学习资源
官方文档与社区支持
高级教程与进阶技巧
附录
常见 SQL 查询示例
正则表达式常用模式
常见日志格式与字段解析示例
推荐本站淘宝优惠价购买喜欢的宝贝:

本文链接:https://www.hqyman.cn/post/11051.html 非本站原创文章欢迎转载,原创文章需保留本站地址!

 微信支付宝扫一扫,打赏作者吧~
微信支付宝扫一扫,打赏作者吧~休息一下~~